
世界模型走了一些弯路
世界模型走了一些弯路「不如直接数字人」 私以为,世界模型这个概念的发展经过了三个非常幽默的阶段。 第一阶段:硅谷真懂行的老登如杨立昆、李飞飞,觉得大语言模型在讲故事上没啥空间了,所以从学术圈拽了个新概念过来尝试弯道超车。
来自主题: AI资讯
7923 点击 2026-07-04 10:51
 搜索
搜索
「不如直接数字人」 私以为,世界模型这个概念的发展经过了三个非常幽默的阶段。 第一阶段:硅谷真懂行的老登如杨立昆、李飞飞,觉得大语言模型在讲故事上没啥空间了,所以从学术圈拽了个新概念过来尝试弯道超车。

打脸了,家人们!!

2020年,吴迪读研一,张启煊念大三,他们跟同为上海科技大学学生的张龙文、曾初啸一起创办了影眸科技。公司早期做过一系列有关3D与生成的探索——做过穹顶光场扫描,做过二次元APP,做过数字人,踩过元宇宙的尾巴,也经历过几乎没有现金流的至暗时刻。

这家专注数字人和AIGC视频生成技术的公司,刚刚迎来一次关键资本加码——旗下AI短剧协作平台AniShort完成近亿元融资,由北京泰中合领投,多家机构跟投,老股东全线加码。而这,也是2026年国内AI短剧工具类产品最大单笔融资纪录。

最近,来自上海创智学院、复旦大学等机构的研究者提出了 Hallo-Live,试图正面解决这个矛盾。论文于 2026 年 4 月 26 日 发布在 arXiv。该方法将 异步双流扩散(Asynchronous Dual-Stream Diffusion) 与 人类偏好引导蒸馏(Human-Centric Preference-Guided DMD) 结合起来
就在今天,美团龙猫大模型团队突然开源了商用级数字人视频生成模型 LongCat-Video-Avatar 1.5。在权威评测中,它的用户偏好胜率全面超越 Kling Avatar 2.0、OmniHuman-1.5 和 HeyGen 这三个头部玩家,并且直接以 MIT 协议开放,连商用限制都懒得设。
时隔近一年,那个在 B 站教大家阅读 AI 论文的大神李沐 @跟李沐学 AI,终于回归了!

上周,我们在热爱远识资本的文章中提到了其代表作:仅靠demo就能实现13.2亿美金估值的Vivix。
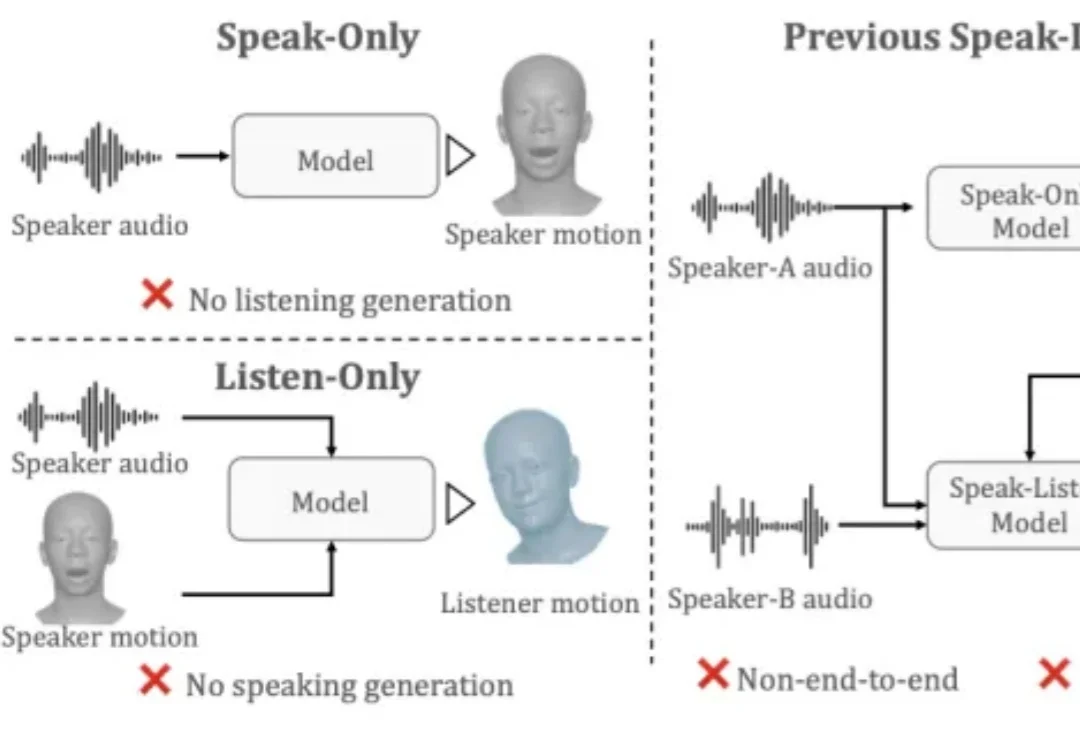
在游戏 NPC、虚拟主播、在线客服等数字人对话场景中,倾听时的 “扑克脸” 问题一直是行业长期痛点 —— 虚拟人说话时口型可以做到精准同步,但倾听时却表情僵硬、毫无反应,严重影响对话的自然感和沉浸感。盛大 AI 研究院(东京)与东京大学联合提出 UniLS(Unified Listening and Speaking),首个仅凭双轨音频即可端到端同时驱动说话和倾听面部动作的统一框架。

当你和 3D 数字人对话时,有没有遇到过这种诡异时刻:它的嘴在动,但表情依旧僵硬;手在挥舞,但和说话内容完全脱节;更糟的是,那种外表像真人但动作不自然的违和感,让人瞬间陷入 “恐怖谷”。