
全球最大数据中心黄了!美国电网卡住AI,GobiX在中国戈壁破局
全球最大数据中心黄了!美国电网卡住AI,GobiX在中国戈壁破局37.7°C,干趴了一台国家级AI超算。6月底,英国遭遇有记录以来最热的六月。剑桥大学的Dawn——全英最快的AI超算之一——冷却系统当场热瘫,上千块GPU被迫休了一周多的高温假,350多个科研项目全线急刹。
来自主题: AI资讯
8041 点击 2026-07-12 10:48
 搜索
搜索
37.7°C,干趴了一台国家级AI超算。6月底,英国遭遇有记录以来最热的六月。剑桥大学的Dawn——全英最快的AI超算之一——冷却系统当场热瘫,上千块GPU被迫休了一周多的高温假,350多个科研项目全线急刹。
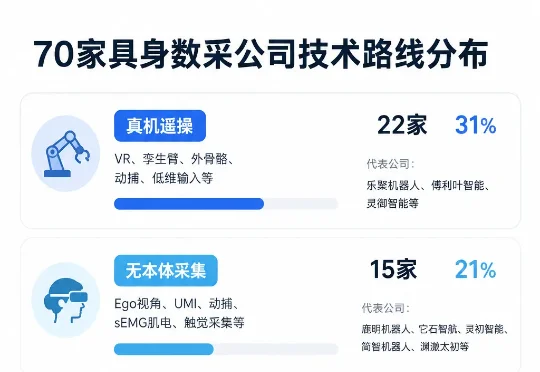
量子位不完全统计了97家国内具身数据玩家的情况,其中70家做数据采集,27家做数据infra。过去一年(2025年7月1日至2026年7月1日),15家「不做本体、不做模型、只做数据的独立具身数据服务商」,共融资约44.7亿元。
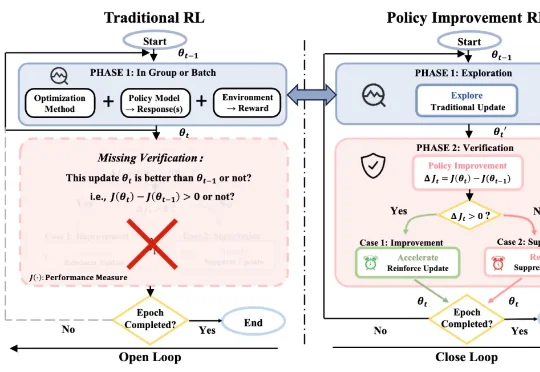
来自北航、北大、美团的研究团队提出了Policy Improvement Reinforcement Learning, PIRL,以及对应的落地算法 PIPO。这项工作关注的是大模型 RL 后训练中一个非常基础、但长期被默认跳过的问题:一次更新在当前数据上看起来优化了学习信号,是否就真的说明模型策略变强了?

微软Copilot & Agents Core总裁Nitin Agrawal说,「迫不及待想让客户看到GPT-5.6能做什么」——不管是起草文档、分析数据、做演示,还是跨团队协作,产出都会更精致。除了原生接入模型,微软还会直接通过OpenAI API调用GPT-5.6,服务Microsoft 365客户。双通道,齐上阵。
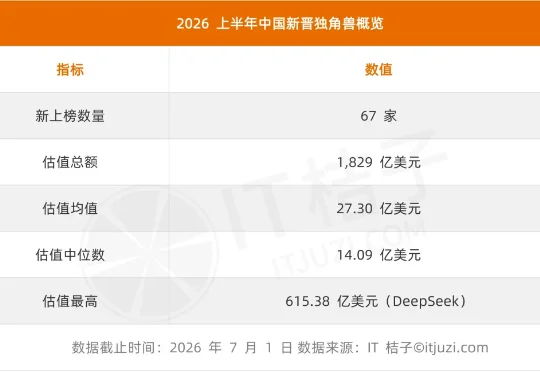
截至 2026 年 7 月 1 日,IT 桔子独角兽数据库信息显示,中国共有 517 家在榜独角兽企业,总估值约 2.39 万亿美元。从估值结构看,呈典型的金字塔分布——57.3% 集中在 10 至 20 亿美元区间,30.8% 在 20 至 50 亿美元,50 亿以上 62 家(12.0%),其中 500 亿美元以上的超级独角兽仅 5 家:
蚂蚁集团旗下具身智能公司蚂蚁灵波,把这块最难的拼图拍上了桌:LingBot-VA 2.0——行业第一个具身原生预训练模型。所谓「具身原生」,一句话说清楚:不是拿现成的数字世界模型做嫁接,而是从数据、训练目标到模型架构,每一层都为「机器人在物理世界干活」而生—
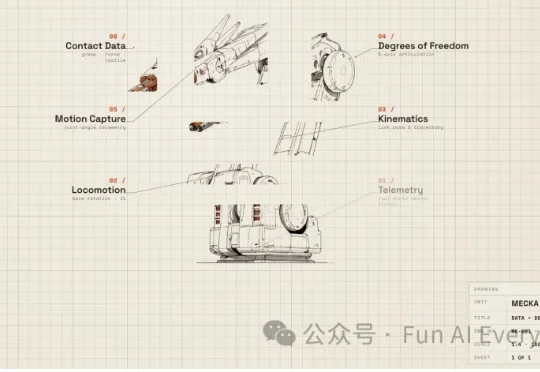
今天分享一家很新的公司,Mecka AI,Mecka AI 是一家给机器人公司提供训练数据的公司。更具体一点,Mecka AI 做的是“人类动作数据”。也就是说,Mecka 做的事情很像“机器人时代的 Scale AI”。
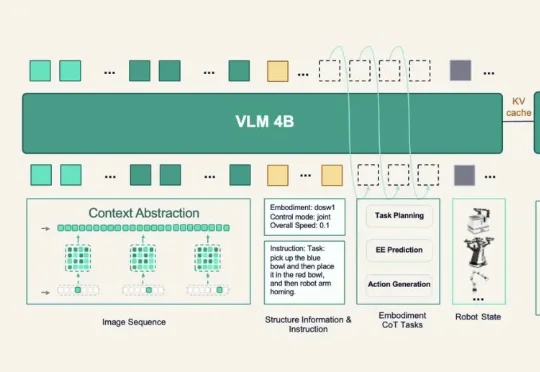
今天的原力灵机开发者大会上,这家公司就把新一代具身基础模型DM0.5端上了桌。 往前,它能接住数据飞轮;往后,它连着开发者平台与真实场景,可以说是后续一切落地动作的底座。
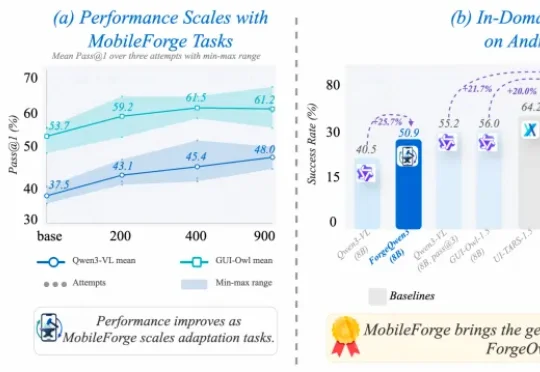
来自浙江大学 APRIL 实验室、快手主站技术部和清华大学的研究团队提出了 MobileForge,试图把手机 GUI Agent 的适配过程变成一个 “无标注、自探索、自反馈、自优化” 的闭环系统。
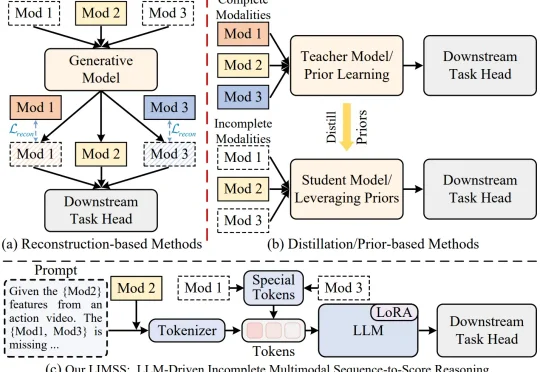
本文是北京大学彭宇新教授团队联合福州大学柯逍教授团队在细粒度多模态动作质量评价领域的最新研究成果,相关论文已被 ICML 2026 接收为 Spotlight,并已开源。真实世界中的多模态数据往往并不完整。在动作质量评价任务中,视频、光流、音频等模态能够从不同角度描述动作执行过程,但在实际采集时,传感器故障、环境噪声、隐私限制等因素都会导致模态缺失。