一个A股老手的Agent实验:在扣子里养出了一个投研助理
一个A股老手的Agent实验:在扣子里养出了一个投研助理朋友向她推荐了字节旗下的扣子。今年3月起,朋友就用扣子自动盯盘、分析、复盘,生成每日投资日报。在她看来,扣子之所以适合投资人,关键在于接入了同花顺、中金、广发等多个数据源,再配合定时任务,能把投研中大量重复、连续的工作沉淀为固定流程。
来自主题: AI资讯
8000 点击 2026-07-10 10:38
 搜索
搜索
朋友向她推荐了字节旗下的扣子。今年3月起,朋友就用扣子自动盯盘、分析、复盘,生成每日投资日报。在她看来,扣子之所以适合投资人,关键在于接入了同花顺、中金、广发等多个数据源,再配合定时任务,能把投研中大量重复、连续的工作沉淀为固定流程。

6 月 30 日,深度机智团队发布论文 Human-as-Humanoid。他们在自研拟人机器人 PrimeU 上,实现了完全没有目标任务真机示范数据的情况下,仅凭从人类视频中转换而来的动作监督,零样本完成了倒水、放环、装袋、叠杯等复杂真实操作任务。

但2026年春招里,她一口气投递了两百多家企业的市场、品牌岗,其中不乏头部互联网公司和4A公关公司,支撑她跨界的底气,是AI工具。改变始于2025年的一段外企实习。当时主管交给她一项任务:对全国3000家线下门店的销售数据做透视分析,输出用户画像报告。放在以前,纯文科背景的她根本接不住这样的需求,但那次她一边找行业案例参考框架,一边对着ChatGPT和Claude边问边学,

有一款 AI 录音器就是这么干的。它叫 Memoket,是这两年扎堆冒出来的 AI 录音硬件里的一个——自带麦克风、电池和 App,一台能独立干活的设备。可它跟你的 Apple Watch 之间,没有半点数据往来——却专门做了个支架,只为把自己牢牢固定在 Apple Watch 旁边。

当机器人后空翻刷屏时,代表小脑已经在快速进展。但你是否意识到,让机器人真正干活卡脖子的从来不是小脑,而是大脑?蚂蚁灵波刚刚开源的LingBot-VLA2.0,用同一套模型「驯服」了20种的机器人构型。行业终于有人开始认真算重复适配成本这笔账了。

根据人社部启动了互联网企业云端招聘月活动的最新数据,今年暑假,超5000家互联网企业集中释放了超过20万个就业岗位。京东、腾讯、字节跳动、美团等头部企业合计贡献超4.6万个岗位,覆盖AI算法、大模型应用、高性能计算等前沿方向。
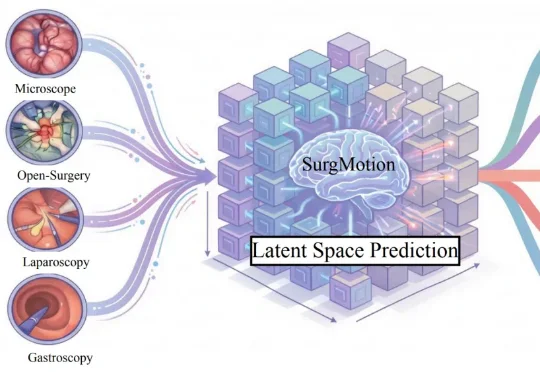
手术 AI 正在从 “单帧感知” 迈向 “全流程视频理解” 的全新时代!近日,由中国科学院香港创新研究院人工智能与机器人创新中心领衔,发布了全球首个十亿级参数、最大规模数据集练成的手术视频原生基础模型 ——SurgMotion!

保险、AI、资本、媒体——四个圈子的人同时出现在一个签约仪式上,只因为一件从没人干过的事:给用户上传给AI的数据上保险。荆华密算与人保北京市分公司、AI原点社区,签下了北京市首单、也是保险行业首个AI企业数据损害赔偿责任保险。

VLA 大模型看似强大,却被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。招商局先进技术研究院下属实验室提出新的移动数据范式,首次在真实机器人系统上证明:让相机动起来采集数据,就能以极低成本破解 VLA 的空间泛化瓶颈,且效果普适于多种主流架构。被一个致命弱点扼住喉咙——相机稍微挪动几毫米,操作成功率就能暴跌一半。

今天,Synthetic Sciences直接发布一款OpenScience的开源替代项目。团队表示,Open Science比 Claude Science 更好用,且完全开源。Open Science支持30个可用的数据库,超250个研究skills。这些数据和技能,让Open Science具备实验假设、消融实验、结果溯源、论文撰写等全套科研能力。