
你选择的基础架构,决定你能长成什么样的 AI 公司
你选择的基础架构,决定你能长成什么样的 AI 公司当 Agent 走向生产,云与数据库需要被一起重新考虑。
来自主题: AI资讯
6109 点击 2026-07-15 14:55
 搜索
搜索
当 Agent 走向生产,云与数据库需要被一起重新考虑。
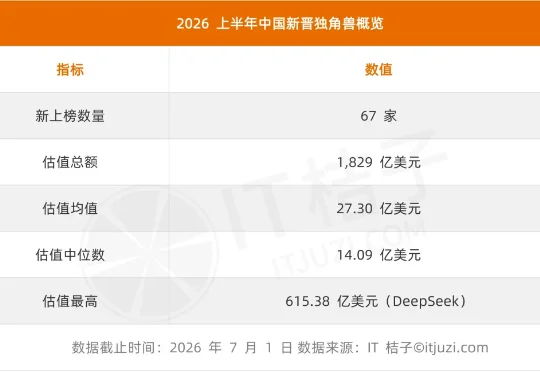
截至 2026 年 7 月 1 日,IT 桔子独角兽数据库信息显示,中国共有 517 家在榜独角兽企业,总估值约 2.39 万亿美元。从估值结构看,呈典型的金字塔分布——57.3% 集中在 10 至 20 亿美元区间,30.8% 在 20 至 50 亿美元,50 亿以上 62 家(12.0%),其中 500 亿美元以上的超级独角兽仅 5 家:

今天,Synthetic Sciences直接发布一款OpenScience的开源替代项目。团队表示,Open Science比 Claude Science 更好用,且完全开源。Open Science支持30个可用的数据库,超250个研究skills。这些数据和技能,让Open Science具备实验假设、消融实验、结果溯源、论文撰写等全套科研能力。
Anthropic 在 6 月 30 日发布了 Claude Science。 如果只看发布稿,这很容易被理解成“Claude 又加了一套科研插件”。但我看完之后,感觉它想做的事情比插件更重一点:它不是只帮你读论文、写代码、画图,而是想把文献、数据库、代码环境、计算资源、图表、手稿和结果审查放进一个连续的科研工作台里。这件事对生信人很有吸引力。
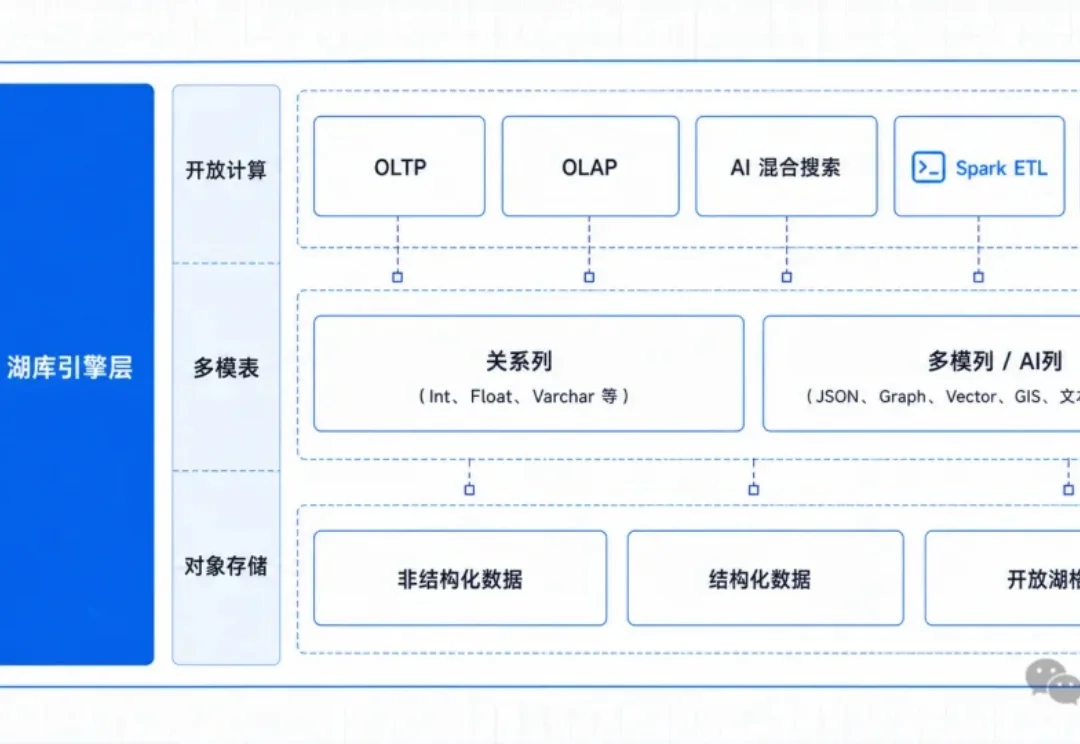
AI时代苟日新,日日新,又日新,数据库也是如此。
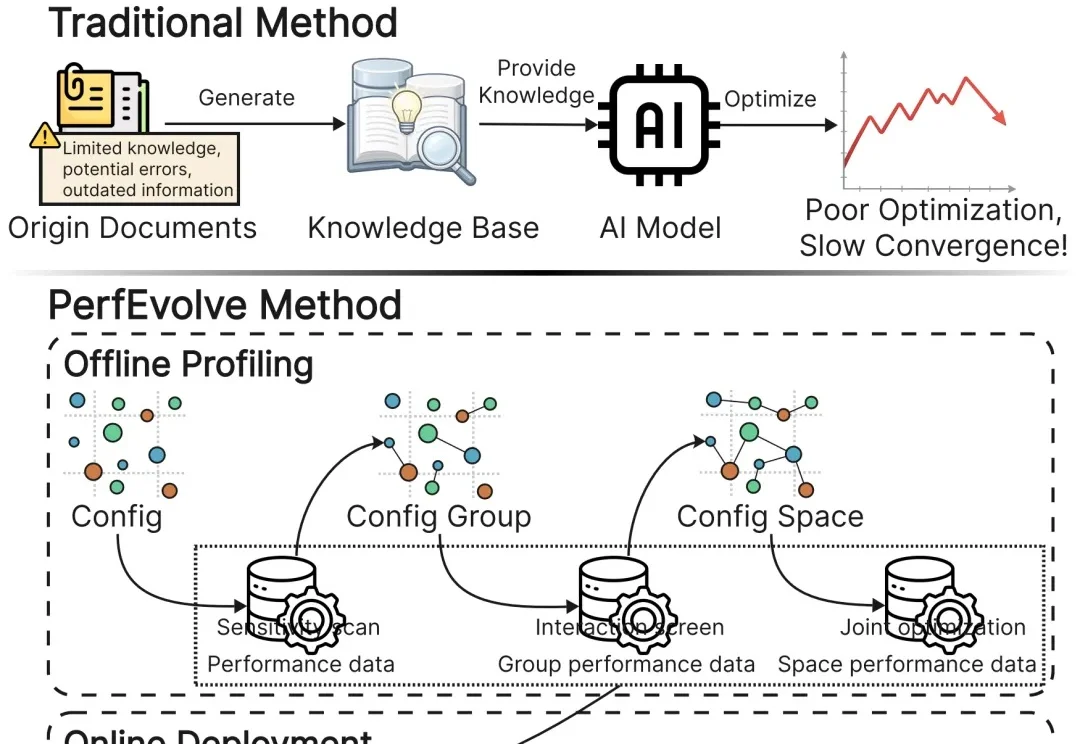
数据库自动调参,一直是大模型Agent的“看似完美、实则翻车”名场面。
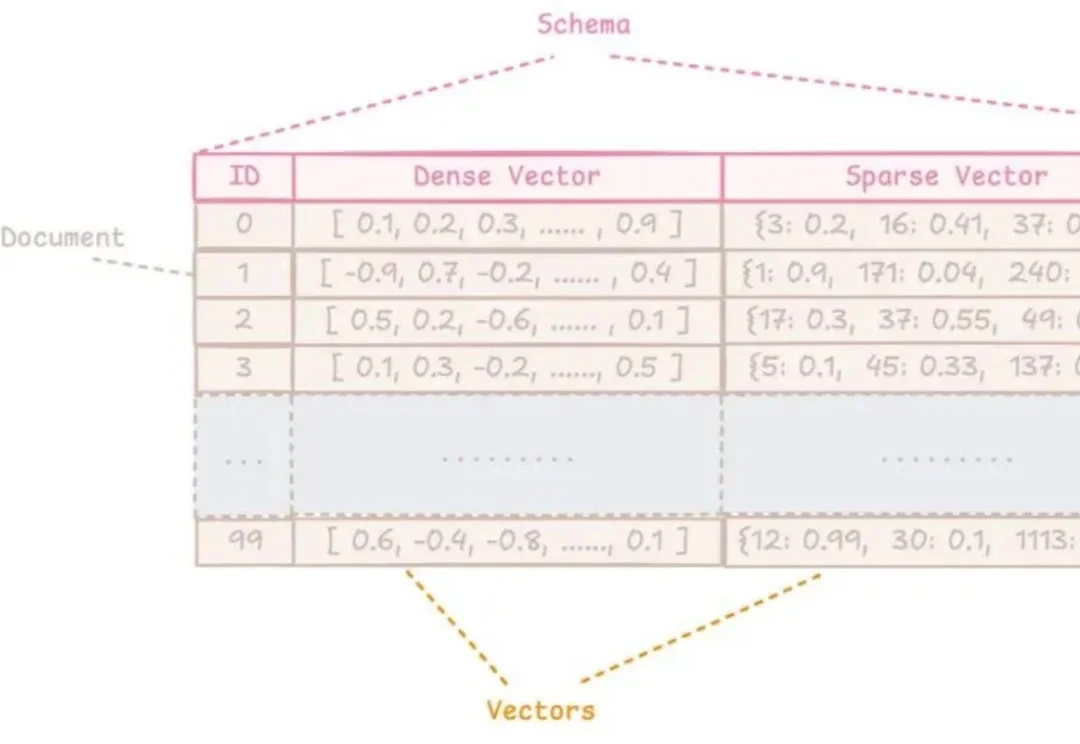
阿里开源的生产级向量数据库,跑在进程里,亿级数据毫秒响应
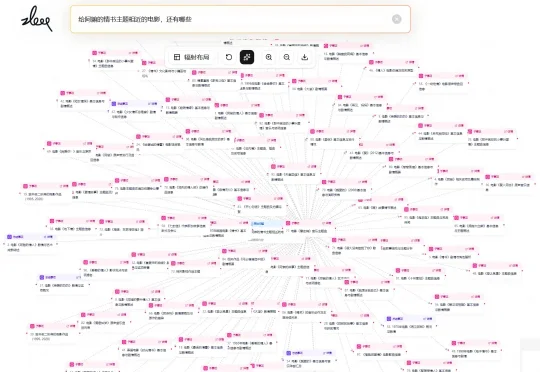
广州智跃深空人工智能科技有限公司 Zleap AI 提出的 SAG(SQL-Retrieval Augmented Generation) 出场了。其实,名字已经点题了——不是 Graph、Hippo,而是 SQL-Retrieval。它的核心想法是在离线阶段,SAG 先把原始文本先整理成「事项 + 实体」的数据库结构。等查询来了,再围绕当前问题,用 SQL 动态串出一张局部线索网。
如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。

顶级AI编码一日千里,到了生物学领域却频频翻车,并非模型不够聪明,而是科学数据库至今只为人类点鼠标而生。