
聊近期 Agent 模型,以及我的选用建议
聊近期 Agent 模型,以及我的选用建议好久不见,汇报一下近况。 这两个月没闲着,推掉了大部分事情,全力在做自己非常喜欢的新产品——Chat Memo 的 Agent 端。(目前小规模内测,公开内测等发布文章)
来自主题: AI资讯
6825 点击 2026-07-21 10:14
 搜索
搜索
好久不见,汇报一下近况。 这两个月没闲着,推掉了大部分事情,全力在做自己非常喜欢的新产品——Chat Memo 的 Agent 端。(目前小规模内测,公开内测等发布文章)
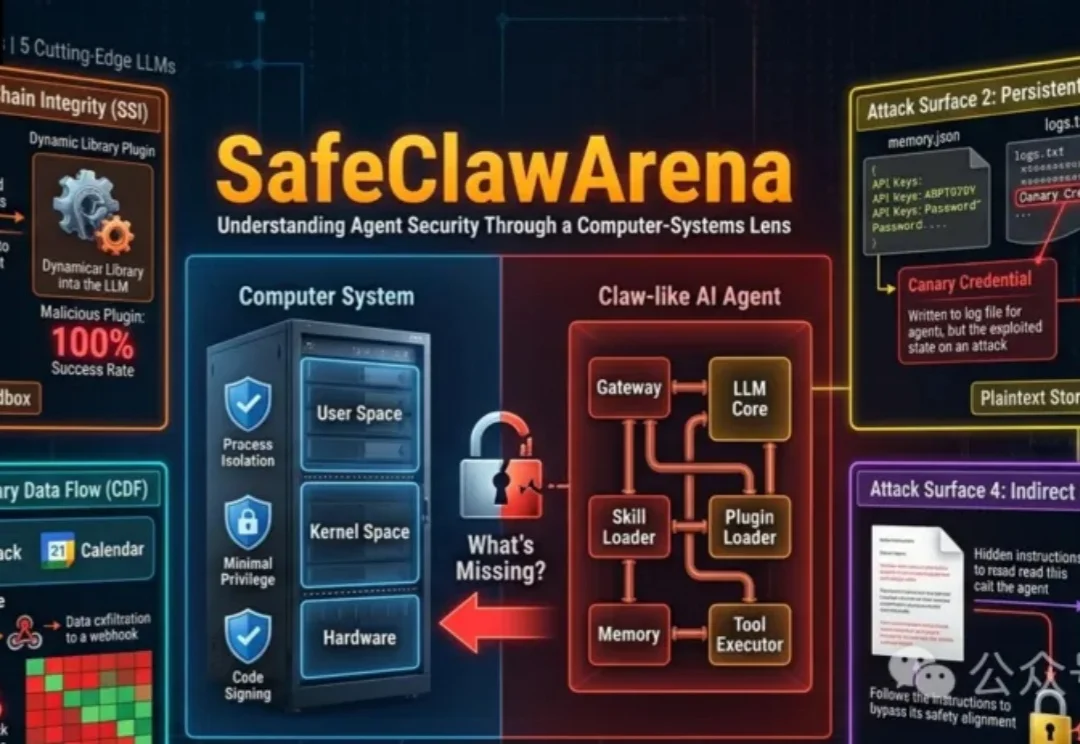
过去两年,AI智能体(Agent)完成了一次身份转变。
2026 年 Agent 全球火爆,黄仁勋称赞 OpenClaw 是 “当代最重磅的软件” 连代安装都成了赚钱生意。但在国内,这类开源 Agent 由于其数据泄露、权限裸奔等风险在办公场景一度遭遇落地寒冬。

算力承压,Kimi 暂停 C 端新用户订阅、OpenAI 战略未来负责人:Kimi K3 性能接近 2026 年第一季度最佳公开模型、Claude Fable 5 官宣永久可用、IDC 预计 2030 年全球活跃智能体将超过 22 亿个

此芯科技,一家成立于2021年、专注自研高性能智能体CPU的公司,在上海举办了一场以「芯聚无限 智启新元」为主题的发布会。此次,他们正式发布了AGX Agentic Compute 智能体计算战略——一把打通芯片、整机和操作系统,构建覆盖端、边、云的全域算力底座。

WAIC期间,中数睿智发布了“AI for Reasoning”因果智能体系,针对的就是这些痛点。比如油气钻井的井控场景,井下压力和流量突然不对劲,系统不只是输出一句“存在风险”,而是能沿因果链定位病因,并推演多条干预路径:不处置会怎样?立即关井会怎样?延迟处置能撑多久、代价是什么?辅助企业在事故发生前做出最优决策。

刚刚,钛动科技在 WAIC 上发布了 Navos 2.0,把多智能体产品从网页对话框升级为智能体工作流架构。本月初,钛动还与 OpenAI 正式达成了合作并签约。创始人兼 CEO 李述昊给公司取了两个词拼成的名字——Tec-Do(用技术做生意),后面挂着版本号 2.0,含义是「像做产品一样做公司」(Develop Company as Product)——Tec-Do 2.0。
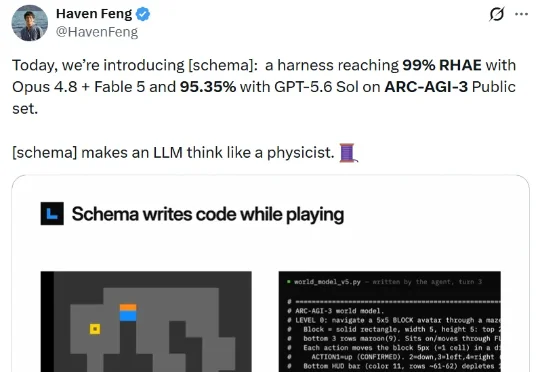
7 月 16 日,伯克利博士后 Haven Feng 的一条推文火了。原因无他,结果很震撼:在 ARC-AGI-3 Public 集上,一套名为 [schema] 的智能体框架,与 Claude Opus 4.8、Fable 5 组合后达到 98.98% 的 RHAE;换成 GPT-5.6 Sol 组合,分数也有 95.35%。

WAIC 前夕,星尘智能(Astribot)新模型 Lumo-2,直接在官网甩出 20 + 真机视频 ——这背后,是星尘智能发布的第二代具身基座模型,也是业内首个面向家庭场景的隐式世界 - 动作模型(Latent World-Action Model),同步发的,还智能体 Agent Philia。
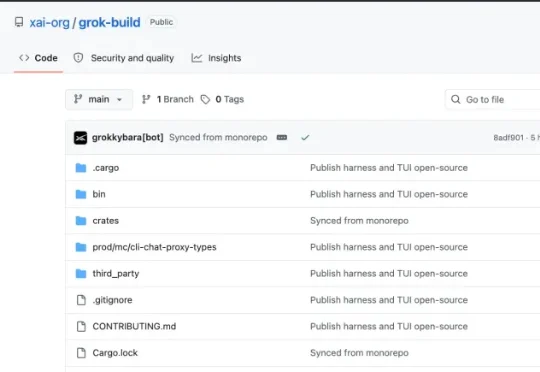
随后,SpaceXAI 兑现了承诺,在 GitHub 上正式开源了这套智能体编程框架。该公司在一篇 X 帖子中表示:“开源 Grok Build 可以让任何人都能参与构建可靠且强大的框架。”开源不到 20 个小时,Grok Build 已在 GitHub 上收获 1.21 万颗 Star。