竞赛编程Agent进入全球前十!南大、清华新模型CF rating超3500
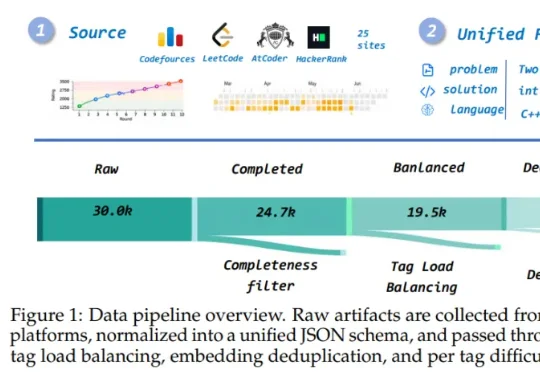
竞赛编程Agent进入全球前十!南大、清华新模型CF rating超3500大语言模型在代码生成上的能力不断增强,但在复杂算法题,尤其是竞赛编程场景中,仍然容易因为算法选择错误、边界条件遗漏、复杂度判断失误或隐藏测试覆盖不足而失败。Solvita是一款面向竞赛编程的智能体框架,通过四个角色(Planner、Solver、Oracle、Hacker)形成闭环系统,并利用可训练的图结构知识网络积累经验。
来自主题: AI技术研报
8764 点击 2026-07-08 15:09