
刚刚,Gemini 3.6 Flash 正式发布,但网友笑得更大声了
刚刚,Gemini 3.6 Flash 正式发布,但网友笑得更大声了如果你从去年就开始用 Gemini,那感觉就像看着自家兄弟慢慢得了阿尔茨海默症。按理说,一家公司发新模型,通常是来打脸这种调侃的。可就在刚刚,Google 一口气发了三个新模型之后,网友非但没收回这句话,反而笑得更大声了。多少有种他们都不看好你,可偏偏你最不争气的即视感。
来自主题: AI资讯
9309 点击 2026-07-22 09:02
 搜索
搜索
如果你从去年就开始用 Gemini,那感觉就像看着自家兄弟慢慢得了阿尔茨海默症。按理说,一家公司发新模型,通常是来打脸这种调侃的。可就在刚刚,Google 一口气发了三个新模型之后,网友非但没收回这句话,反而笑得更大声了。多少有种他们都不看好你,可偏偏你最不争气的即视感。

今天,阿里通义团队发布了他们第三代图像生成模型:Qwen-Image-3.0 。官方博客用了一个字来概括这一代的核心进步,「实」。不是好看,不是炫技,是「实」。内容丰实、细节真实、知识厚实。
Vivix到底在做什么?这是过去一年多以来,AI圈对这家神秘公司的最大好奇。但很少有人能说清楚这家公司到底在做什么。有人说,这是一个不做模型的纯AI产品公司,要做“下一个时代的抖音”,所以才频频推出如7verse、TipTap这样的互动娱乐产品。如果你在这段时间搜索Vivix——唯一可见的技术方向介绍,只有官网写着的“下一代视觉生成引擎”。

商品交易恰好是一个通用的竞技场——精准地判断一件商品的真假、成色和估价,不是互联网上能搜到的信息,而是面向交付的生产过程中形成的专家数据。这个场景里生长出了一家提供垂直模型、数据和服务的公司——图灵深视。这家由清华大学孵化的公司,想实现一个简单的愿景:用 AI 守护商品交易信任。

“「出海四巨头」智谱、Kimi、千问......谁最受外企欢迎? ” 作者丨胡清文 编辑丨徐晓飞 去年这个时候,硅谷讨论的还是中国模型能不能打。但在今年,这个问题已经被一组数据碾过。 OpenRout
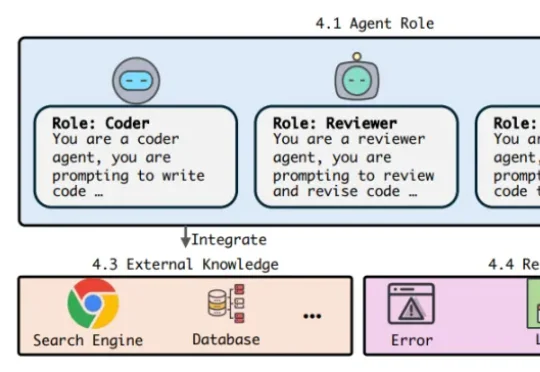
多智能体系统(Multi-Agent Systems,MAS)展示了令人印象深刻的能力:一个模型负责提出方案,另一个模型进行批评,还有模型承担投票、规划或执行。通过角色分工和多轮协作,系统能够解决单个模型难以稳定完成的数学推理、代码生成和知识问答任务。

外界第一次认识苏度,是在今年 4 月。彼时,sudo R1 的开放物体抓取能力给行业留下深刻印象:在开放环境中面对随机物体,机器人能够稳定完成抓取。抓取,这是一个足够基础、又足够难的技能。
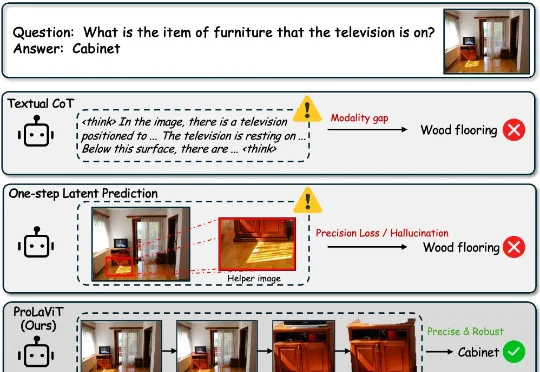
针对这一挑战,腾讯内容服务部 BAC 提出了一个名为 ProLaViT(Progressive Latent Visual Thought) 的全新框架。它的核心思想是:别急着下结论,先在连续隐空间里像人一样「步步推导」。 即让模型遵循 「定位 → 聚焦 → 分离」(Locate → Focus → Isolate) 的因果链,逐步收紧视觉注意力,最终精准锁定目标。

昨天看到了一篇论文,特别有意思,让我连夜读完了。

模型决定起点,数据定义终局。