
大模型给图片打分不再“靠嘴说”!结构图、频谱图当“物证”,用“视觉证据”来给图片打分 | ECCV‘26
大模型给图片打分不再“靠嘴说”!结构图、频谱图当“物证”,用“视觉证据”来给图片打分 | ECCV‘26让大模型给一张图片打“质量分”,它其实经常看走眼。
来自主题: AI技术研报
7040 点击 2026-07-20 14:59
 搜索
搜索
让大模型给一张图片打“质量分”,它其实经常看走眼。

“芯片的定价权越强,模型和应用公司的成本刚性就越难消解。” 当下,仅豆包一家大模型的日均Token调用量就已突破180万亿;国家数据局的统计显示,全国日均调用量在今年3月已超过140万亿——无论从哪个口径衡量,这都是一条两年内从“近乎为零”飙涨超千倍的曲线。
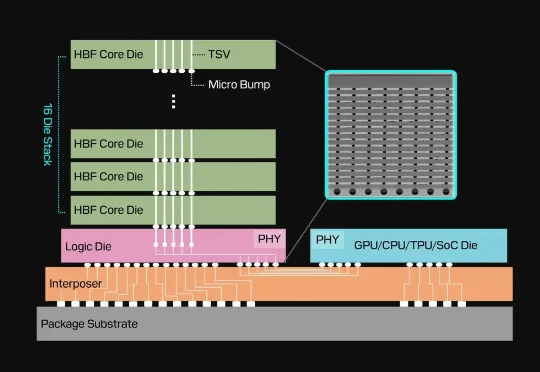
IEEE最新刊发了一条挺反常识的新思路:大模型的内存焦虑,可能要靠U盘里的同款技术来缓解了。没错,就是NAND Flash。但现在,SanDisk和SK海力士正在推动一种新东西:High Bandwidth Flash(高带宽闪存),简称HBF。

AI体育赛道今年迎来了一波明星资本的押注。

人工智能(AI)模型在科学发现中的角色,正经历着一场从「工程缝合者」向「智能推演者」的深刻蜕变。
过去一年,Deep Research Agent 被视为大模型落地的下一个突破口,它们会检索、能用工具、可多步推理,在一个个榜单上高歌猛进。但把它们放到真实世界的专业场景里,表现是否也同样亮眼?

市面上已有几十种Agent记忆方案,有的基于向量检索,有的基于知识图谱,有的靠定期总结“压缩”对话,有的则完全依赖模型自身的上下文窗口。它们各有各的说法,但在系统层面,到底哪种方案靠得住?哪种方案在你的工作负载下既不贵又准?

算力承压,Kimi 暂停 C 端新用户订阅、OpenAI 战略未来负责人:Kimi K3 性能接近 2026 年第一季度最佳公开模型、Claude Fable 5 官宣永久可用、IDC 预计 2030 年全球活跃智能体将超过 22 亿个
为一个纯外行,如果你想从0开始,用国产模型,徒手搓出一个完全属于自己的产品,应该需要哪些步骤和流程,还有一些乱七八糟的坑。先叠甲一下,下面这套流程,是我自己作为非专业者,目前跑得比较舒服的一条路径,主要面向完全不懂代码、想先把第一个产品做出来的人。不同类型的产品,可以选择不同的托管平台,工程团队也会有不同的开发规范。
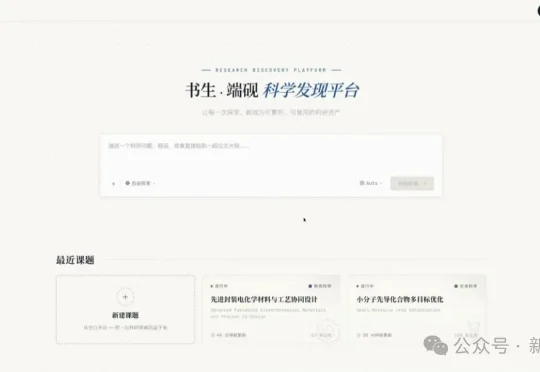
WAIC 2026,上海 AI 实验室发布了「书生·端砚」科学发现平台,有望为长期存在的科研结构性矛盾提供一种新的思路与解决方案。区别于行业内多数产品依托大模型适配科研场景、实现浅层提效的优化模式,「书生·端砚」以干湿实验闭环迭代、科研资产沉淀为核心能力,补齐 AI 科研缺失的真实场景反馈链路,推动 AI 科研应用从单点效率优化,迈向科研范式升级的全新阶段。