
世界模型应如何评估?南京大学团队发布「世界模型」评估立场论文
世界模型应如何评估?南京大学团队发布「世界模型」评估立场论文近期,围绕「世界模型」的讨论持续升温。机器人、自动驾驶、视频生成、具身智能等多个方向都在频繁使用这一概念,相关系统不断出现,演示形式日益丰富,评价指标也越来越多。伴随这一趋势,一个基础问题变得格外重要:当一个模型被称为「世界模型」时,人们究竟在评价什么?
来自主题: AI技术研报
8263 点击 2026-07-13 14:44
 搜索
搜索
近期,围绕「世界模型」的讨论持续升温。机器人、自动驾驶、视频生成、具身智能等多个方向都在频繁使用这一概念,相关系统不断出现,演示形式日益丰富,评价指标也越来越多。伴随这一趋势,一个基础问题变得格外重要:当一个模型被称为「世界模型」时,人们究竟在评价什么?

这不是科幻小说,而是 METR(模型评估与训练研究组织)联合Anthropic、Google、Meta和OpenAI 进行内部红队测试后,发布的首份《前沿风险报告》中披露的真实案例。这是四大巨头第一次允许第三方深入测试他们内部最强、可访问完整思维链(CoT)的模型,并开放非公开的对齐与控制信息。
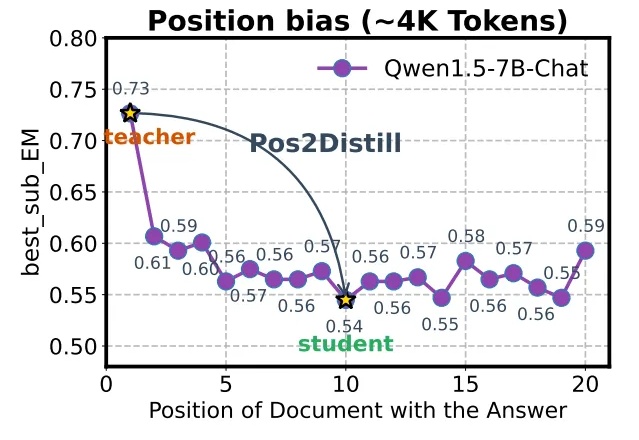
语言模型遭遇严重的位置偏见,即模型对不同上下⽂位置的敏感度不⼀致。模型倾向于过度关注输⼊序列中的特定位置,严重制约了它们在复杂推理、⻓⽂本理解以及模型评估等关键任务上的表现。
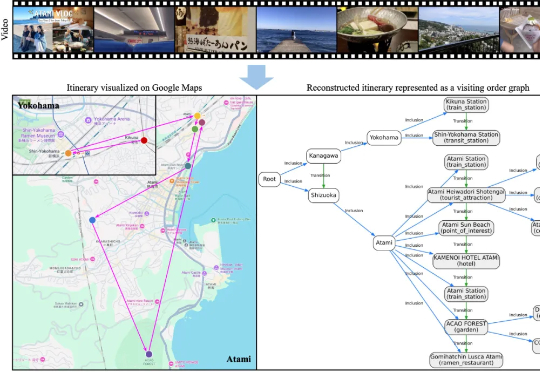
大家或许都有过这样的体验: 看完一部喜欢的动漫,总会心血来潮地想去 “圣地巡礼”;刷到别人剪辑精美的旅行 vlog,也会忍不住收藏起来,想着哪天亲自走一遍同样的路线。旅行与影像的结合,总是能勾起人们的
AI 下半场,模型评估比模型训练更重要。我们需要从根本上重新思考评估的方式。

总部位于首尔的 Datumo 最初是一家 AI 数据标注公司,如今致力于通过提供工具和数据来帮助企业构建更安全的 AI 系统。
Toloka是一家专注于AI数据标注与模型评估的众包平台,成立于2014年,创始人Olga Megorskaya曾是俄罗斯科技巨头Yandex董事会成员。公司总部位于阿姆斯特丹,之前由AI基础设施公司Nebius Group控股。

科技媒体 maginative 今天(4 月 16 日)发布博文,报道称 OpenAI 宣布收购 Context.ai团队,后者是一家由 GV 支持的初创公司,以评估和分析 AI 模型见长。Context.ai的联合创始人 Henry Scott-Green(首席执行官)和 Alex Gamble(首席技术官)将加入 OpenAI,专注于研发模型评估工具。

能够深入大模型内部的新评测指标来了! 上交大MIFA实验室提出了全新的大模型评估指标Diff-eRank。 不同于传统评测方法,Diff-eRank不研究模型输出,而是选择了分析其背后的隐藏表征。

在LLM能力突飞猛进的当下,所有研究者似乎都在关注数据、算力、算法等模型开发的各个方面,但OpenAI研究员Jason Wei最近发布的一篇博客文章提醒我们,模型评估的工作同样非常重要。如何开发出优秀的评估测试,对AI能力的发展方向至关重要。