最懂医疗的国产推理大模型,果然来自百川智能
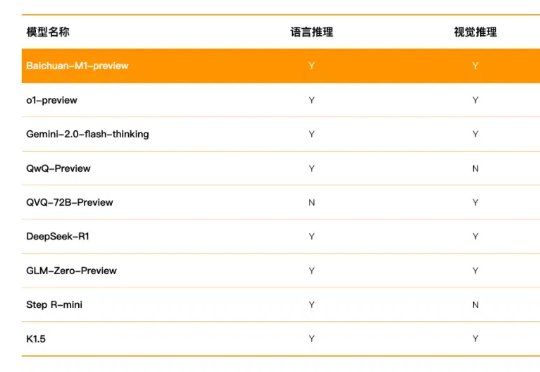
最懂医疗的国产推理大模型,果然来自百川智能就在本周,Kimi 的新模型打开了强化学习 Scaling 新范式,DeepSeek R1 用开源的方式「接班了 OpenAI」,谷歌则把 Gemini 2.0 Flash Thinking 的上下文长度延伸到了 1M。1 月 24 日上午,百川智能重磅发布了国内首个全场景深度思考模型,把这一轮军备竞赛推向了高潮。
来自主题: AI资讯
8325 点击 2025-01-26 12:16
 搜索
搜索
就在本周,Kimi 的新模型打开了强化学习 Scaling 新范式,DeepSeek R1 用开源的方式「接班了 OpenAI」,谷歌则把 Gemini 2.0 Flash Thinking 的上下文长度延伸到了 1M。1 月 24 日上午,百川智能重磅发布了国内首个全场景深度思考模型,把这一轮军备竞赛推向了高潮。

刚刚发布的豆包大模型1.5,不仅多模态能力全面提升,霸榜多个基准;更难得的是,它在训练过程中从未使用过任何其他模型生成的数据,坚决不走蒸馏「捷径」。
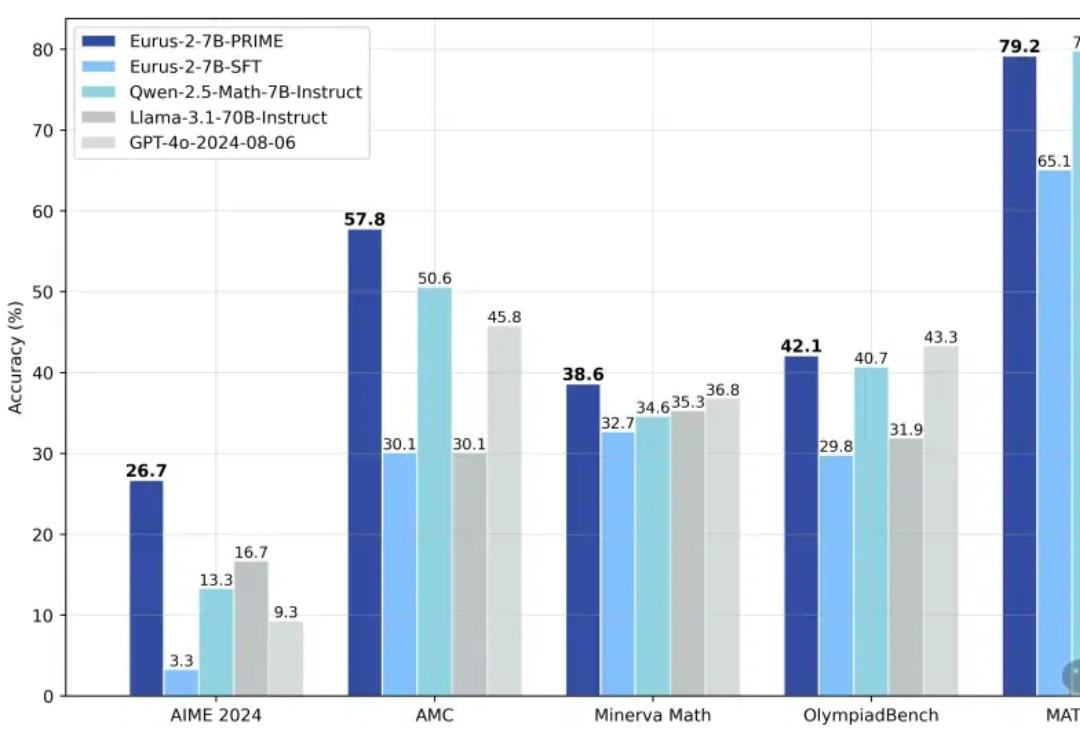
OpenAI o1和o3模型的发布证明了强化学习能够让大模型拥有像人一样的快速迭代试错、深度思考的高阶推理能力,在基于模仿学习的Scaling Law逐渐受到质疑的今天,基于探索的强化学习有望带来新的Scaling Law。

2024 年的最后一天,智谱 GLM 模型家族迎来了一位新成员——GLM-Zero 的初代版本 GLM-Zero-Preview,主打深度思考与推理。

近日,在多知OpenTalk第48期“全球起航!‘教育+AI’出海进行时”活动上,嗨你好教育创始人李晓兵分享了一年来的创业历程和关于外国人学中文这一市场的深度思考。

近期,LLM领域有不少关于系统1和系统2思考的讨论,在Agent方向上这方面的讨论还很少。如何让AI agents既能快速响应用户,又能进行深度思考和规划,一直是一个巨大的挑战。
大模型下半场,新范式开启?