人大系团队、天使轮数千万元融资,境瞳科技给人类社会建一个「世界模型」
人大系团队、天使轮数千万元融资,境瞳科技给人类社会建一个「世界模型」社会智能公司境瞳科技近日完成数千万元人民币天使轮融资,投资方包括英诺天使基金、水木清华校友种子基金、零以创投和驰星创投。这笔钱将主要用来扩大社会模拟器的规模,为社会世界模型的预训练做准备。
来自主题: AI资讯
8991 点击 2026-07-27 11:29
 搜索
搜索
社会智能公司境瞳科技近日完成数千万元人民币天使轮融资,投资方包括英诺天使基金、水木清华校友种子基金、零以创投和驰星创投。这笔钱将主要用来扩大社会模拟器的规模,为社会世界模型的预训练做准备。

以往的空间音频模型,要么受限于实验室的苛刻采集条件,要么被高昂的人工标注成本卡住脖子。而团队的核心洞察是:相机的自运动本身就是一种免费的监督信号。当相机转动时,声源在声场中的相对位置随之改变——这种变化无需人工标注,模型即可从中学习空间对应关系。这项工作入选CVPR 2025 Highlight,投稿论文前2%。

最近,DeepSeek 接连上了几次热搜。先是因为一张实习 offer 引发围观。一位清华学生在社交媒体晒出录用信息,岗位是 DeepSeek 实习生,税前日薪 5500 元。按每月 22 个工作日计算,月薪超过 12 万元。

金涛今年 26 岁,还是清华在读博士。真正把他带进「推理加速」的,是一个很朴素的判断——当大家都默认 FlashAttention 已经把 Attention 算子做到极致时,他却发现:显卡上明明还有更快的计算单元没被用起来 ——「这么明显的收益,为什么没人做?」

近日,来自清华大学等单位的研究团队提出了AutoMIA,一种自动生成镜像错觉艺术的 AI 设计方法,用户仅需任意指定两张图片,分别对应镜子前和镜子中的图案,AutoMIA就可以自动完成3维艺术品的设计,并且支持直接3D打印出来制作艺术品。

投资界从投资方处获悉,智谱已完成对AI基础设施企业中科加禾(XCore Sigma)的战略收购,缔造智谱近年最大的收购案例之一。这次被智谱买下的是一支编译器团队。中科加禾成立于2023年,创始人崔慧敏是清华计算机系毕业生、中科院计算所研究员、博士生导师,也是这一硬核技术领域为数不多走向创业一线的女性学者。

联想之星、银杏谷资本、啟赋资本等投了。
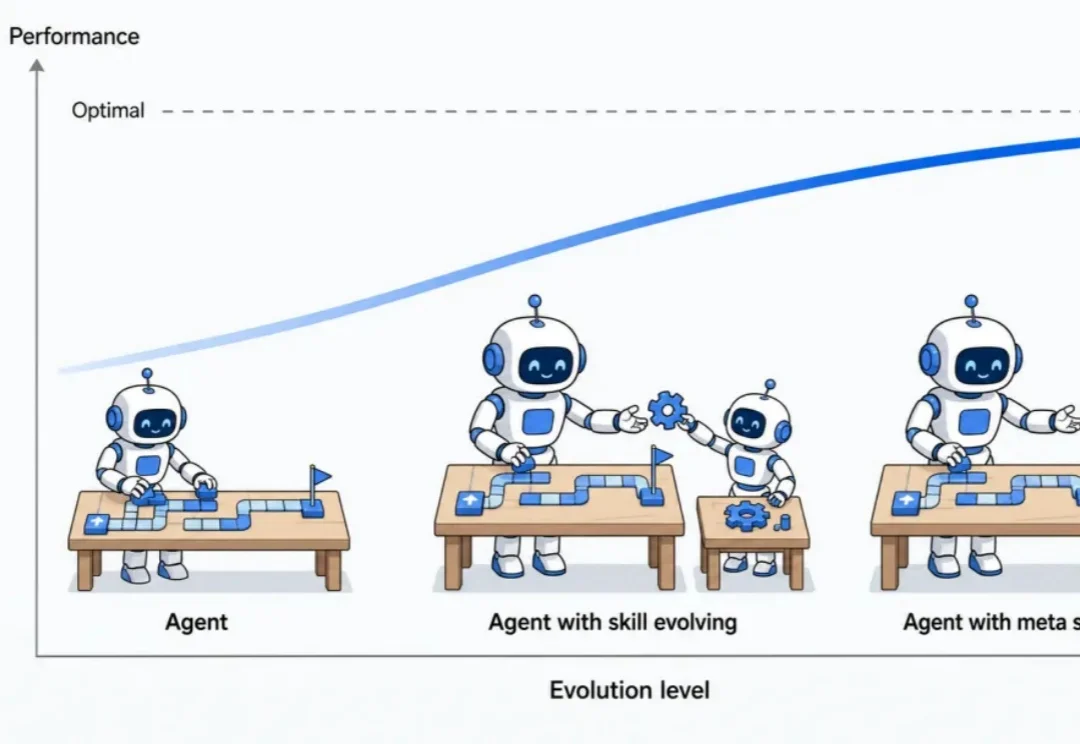
当大模型 Agent 被部署到工具调用、长程任务和开放环境中,一个关键问题会随之出现:能否在不更新模型参数的情况下,将执行经验沉淀下来,并在下一次做得更好?

今天,世界模型几乎成为 AI 领域最受关注的话题之一,但对于“什么才是真正的世界模型”却依然存在巨大分歧。有人认为它只是视频生成的延伸,也有人认为只有能够理解物理规律、支持机器人行动的系统才是真正的世界模型。

袁博地的答案是否定的。从清华大学接触计算机视觉,到 UC Berkeley 攻读 AI 博士,再到 Google X 负责机器人的视觉系统,袁博地过去十多年的研究几乎始终围绕 Pixel 展开:从图像识别,到 GAN、Diffusion,再到图像和视频生成,技术范式不断变化,研究对象却始终指向同一件事——如何让机器理解和生成视觉世界。