
阿里通义发布第三代图像生成模型Qwen-Image-3.0,一手实测
阿里通义发布第三代图像生成模型Qwen-Image-3.0,一手实测今天,阿里通义团队发布了他们第三代图像生成模型:Qwen-Image-3.0 。官方博客用了一个字来概括这一代的核心进步,「实」。不是好看,不是炫技,是「实」。内容丰实、细节真实、知识厚实。
来自主题: AI资讯
8236 点击 2026-07-21 22:20
 搜索
搜索
今天,阿里通义团队发布了他们第三代图像生成模型:Qwen-Image-3.0 。官方博客用了一个字来概括这一代的核心进步,「实」。不是好看,不是炫技,是「实」。内容丰实、细节真实、知识厚实。
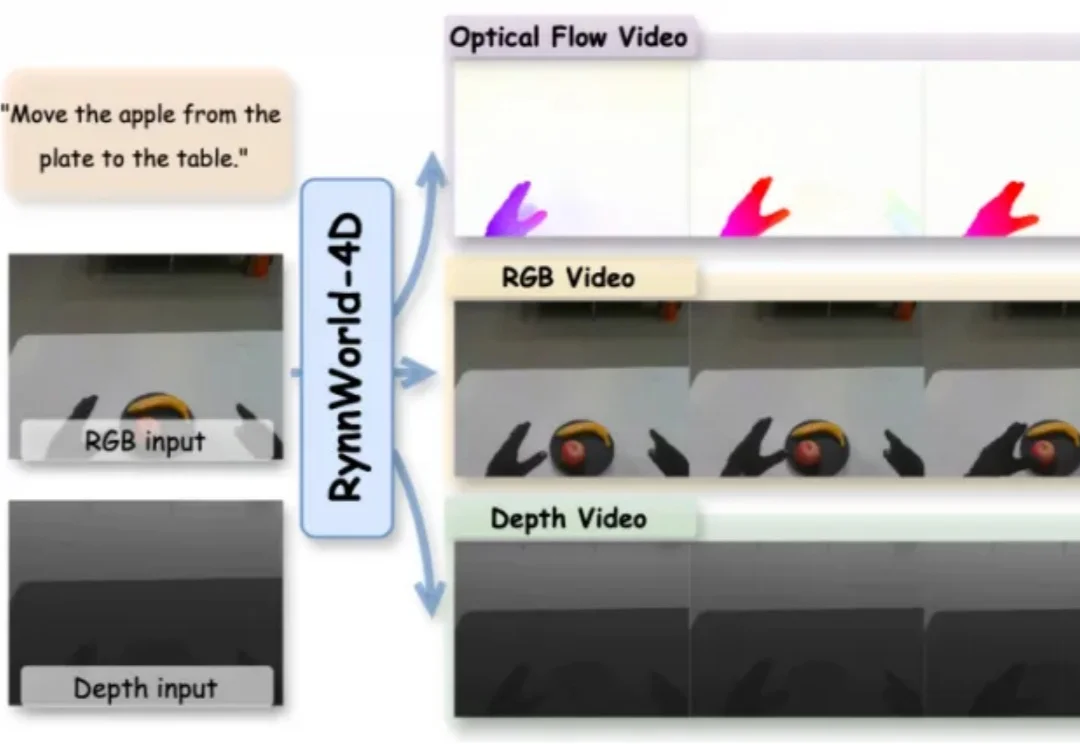
近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。
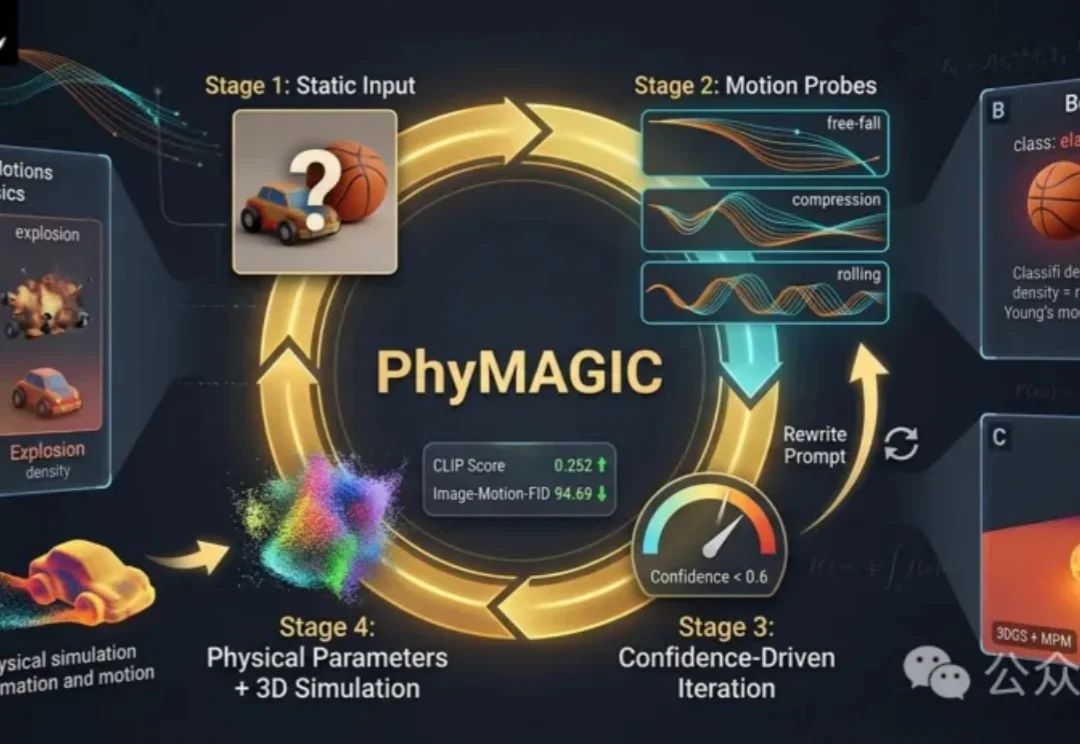
PhyMAGIC通过让物体动起来,从视频中提取物理证据,帮助准确推断材料属性。它结合图生视频与视觉语言模型,生成针对性运动探针,并不断修正物理参数,最终构建出可微分的3D动态模型,实现更符合现实的视频生成。

Meta超级智能实验室(MSL)扔出了首个图像生成模型Muse Image,代号「芒果」(Mango)。这是我们迄今为止最先进的图像生成模型。与Muse Image一同亮相的,还有视频模型Muse Video,目前仍是预览版。

Meta 旗下的超智能实验室 Meta Superintelligence Labs 推出了图像生成模型 Muse Image,并同步预览了 Muse Video。目前,Muse Image 已经接入 Meta AI 应用、网页端以及部分地区的社交平台,Muse Video 也即将向创作者开放。
最近《在超市后门抽烟的二人》这部剧挺火的,尤其是里面的音乐我很喜欢,所以就想着做一个真人版音乐短片,正好发现美图旗下的 MVLAND 上线了创意画布模式,接入 Seedance2.0、可灵、HappyHorse 等顶尖视频生成模型。
火山引擎今天上线了全新的语音模型—— 豆包音频生成模型 1.0(Seed-Audio 1.0)。

新模型上线首月,订阅用户与 ARR 的环比增速均超 400%。 文|王欣逸 编辑|张雨忻 2026 年开年来,3D 生成模型赛道相当热闹。 今年第一季度,影眸科技发布首个 3D 编辑模型 Rodin

今天,阿里巴巴发布了其最新一代视频生成模型HappyHorse 1.1(快乐小马1.1)。阿里称,相比HappyHorse 1.1,这代模型在动态表现力、主体一致性、指令遵循、视觉质感和音频能力等维度有了一定提升。

大语言模型的RL技术已日趋成熟,多模态生成模型的强化学习训练却仍在“各自为战”——图像扩散模型一套流程、视频生成另一套标准、VLM和LLM又有不同的技术栈。