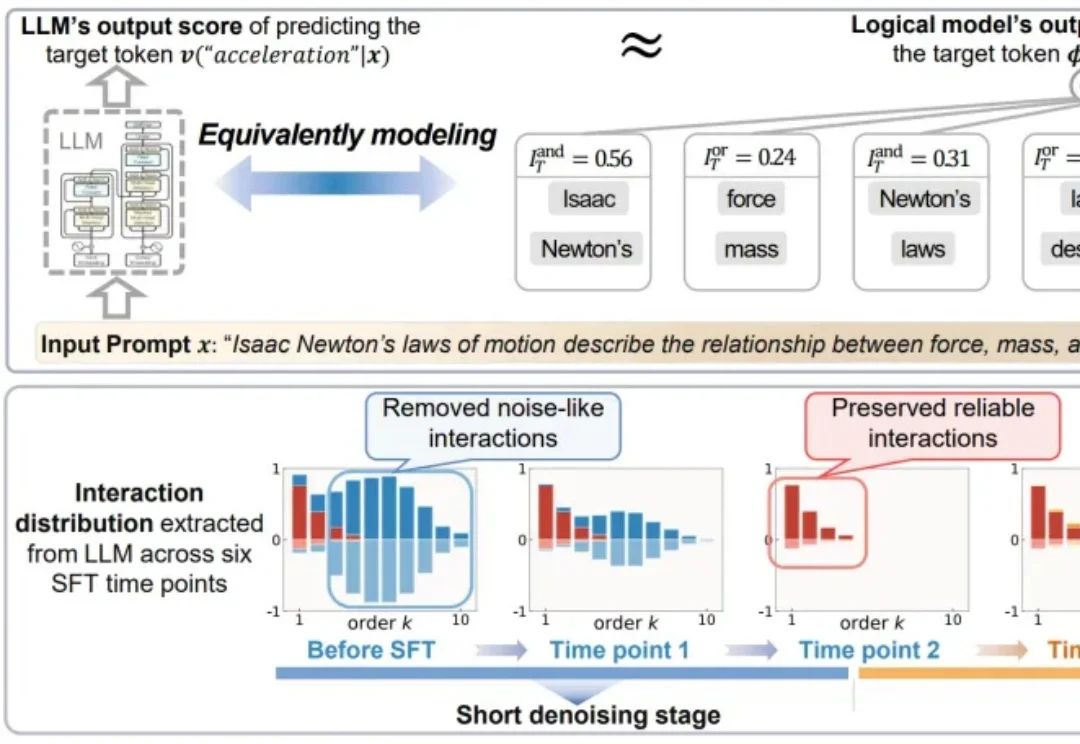
吃透大模型SFT底层机理:终结实践争议,规避无效算力
吃透大模型SFT底层机理:终结实践争议,规避无效算力长期以来,监督微调(Supervised Fine-Tuning,SFT)一直是深度神经网络中最常用的模型适配手段。在中小规模的传统神经网络中,SFT 通常能够稳定提升下游任务表现。
来自主题: AI技术研报
6725 点击 2026-06-04 08:38
 搜索
搜索
长期以来,监督微调(Supervised Fine-Tuning,SFT)一直是深度神经网络中最常用的模型适配手段。在中小规模的传统神经网络中,SFT 通常能够稳定提升下游任务表现。

过去十年,大模型世界里很多最关键的技术路线背后,都能看到Andrew Dai的身影。从早期预训练与监督微调,到后来主流的MoE(Mixture of Experts)架构;从Google Brain最初只有几十人的研究时代,到后来支撑Gemini的大规模数据体系,这位在 Google 工作超过14年的研究科学家,几乎站在了大模型时代每一次关键转折的现场。

在大模型后训练阶段,监督微调(SFT)和强化学习(RL)是两根不可或缺的支柱。SFT 利用高质量的离线(Off-policy)数据快速注入知识,但受限于静态数据分布,泛化能力往往容易触及天花板并带来灾难性遗忘;RL 则允许模型在探索中不断自我迭代,产生与当前策略同分布(On-policy)的数据,上限极高,但往往伴随着训练极度不稳定、计算资源消耗巨大的痛点。

长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。

在大模型微调实践中,SFT(监督微调)几乎成为主流流程的一部分,被广泛应用于各类下游任务和专用场景。比如,在医疗领域,研究人员往往会用领域专属数据对大模型进行微调,从而显著提升模型在该领域特定任务上的表现。

在具身智能领域,视觉 - 语言 - 动作(VLA)大模型正展现出巨大潜力,但仍面临一个关键挑战:当前主流的有监督微调(SFT)训练方式,往往让模型在遇到新环境或任务时容易出错,难以真正做到类人般的泛化

既然后训练这么重要,那么作为初学者,应该掌握哪些知识?大家不妨看看这篇博客《Post-training 101》,可以很好的入门 LLM 后训练相关知识。从对下一个 token 预测过渡到指令跟随; 监督微调(SFT) 基本原理,包括数据集构建与损失函数设计;
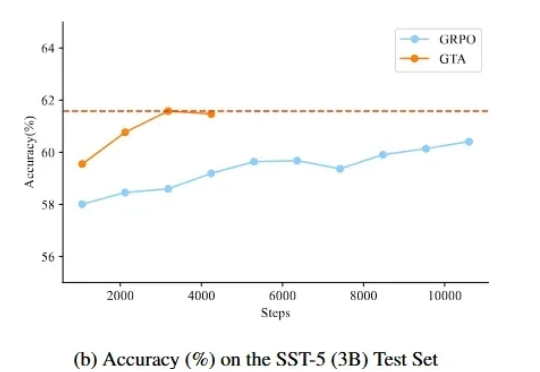
监督微调(SFT)和强化学习(RL)微调是大模型后训练常见的两种手段。通过强化学习微调大模型在众多 NLP 场景都取得了较好的进展,但是在文本分类场景,强化学习未取得较大的进展,其表现往往不如监督学习。
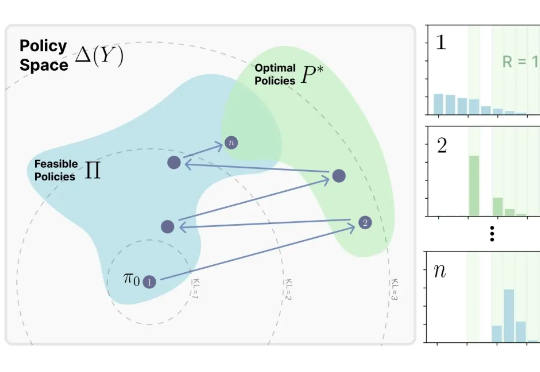
来自MIT Improbable AI Lab的研究者们最近发表了一篇题为《RL's Razor: Why Online Reinforcement Learning Forgets Less》的论文,系统性地回答了这个问题,他们不仅通过大量实验证实了这一现象,更进一步提出了一个简洁而深刻的解释,并将其命名为 “RL's Razor”(RL的剃刀)。
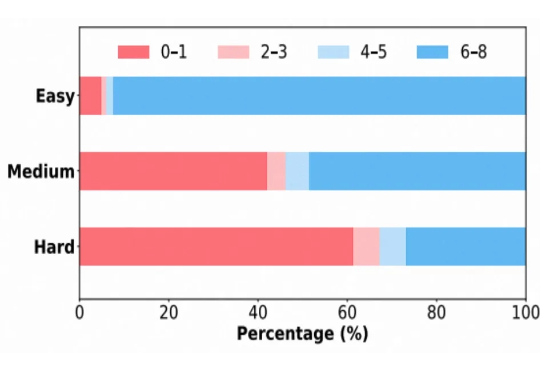
近年来,强化学习(Reinforcement Learning, RL)在提升大语言模型(LLM)复杂推理能力方面展现出显著效果,广泛应用于数学解题、代码生成等任务。通过 RL 微调的模型常在推理性能上超越仅依赖监督微调或预训练的模型。