
刚刚,业界首个RISC-V AI算力超节点方案,奕行智能首秀WAIC 2026
刚刚,业界首个RISC-V AI算力超节点方案,奕行智能首秀WAIC 2026在WAIC 2026期间,国内RISC-V AI算力芯片独角兽——奕行智能,交出了一份里程碑式答卷,其完整展示了从Epoch自研芯片、超节点到全栈软件的系统级方案,并亮出业界首个RISC-V AI算力超节点。
来自主题: AI资讯
9233 点击 2026-07-20 09:46
 搜索
搜索
在WAIC 2026期间,国内RISC-V AI算力芯片独角兽——奕行智能,交出了一份里程碑式答卷,其完整展示了从Epoch自研芯片、超节点到全栈软件的系统级方案,并亮出业界首个RISC-V AI算力超节点。

此芯科技,一家成立于2021年、专注自研高性能智能体CPU的公司,在上海举办了一场以「芯聚无限 智启新元」为主题的发布会。此次,他们正式发布了AGX Agentic Compute 智能体计算战略——一把打通芯片、整机和操作系统,构建覆盖端、边、云的全域算力底座。

过去,大家围着国产芯片问的是,峰值算力多少?制程多少纳米?和英伟达相比差多少? 走到清微智能的展位前,你会发现一件有意思的事:这里摆的不只是芯片。可重构芯片、4K超节点、RAISA软件栈、行业应用,被放在一起呈现——像是在回答所有国产芯片厂商都绕不开的问题:

50多个智算中心,超过1000 EFLOPS的智能算力规模,平均利用效率却远远没有跑满。是石给出的解法,叫拓元(Vectron),一座国产Token优化工厂。是石科技依托国家级计算中心工程经验积淀,持续投入大规模集群研发,建设万卡级国产大集群,持续稳定运营,优化推理效率,构筑了深厚壁垒

我们获悉,近期搜狗前COO、百川智能联合创始人茹立云,已经正式离开百川智能,并以慧辰股份总裁的身份在AI应用及算力资源等业务上开启新尝试。这意味着,百川最早一起并肩作战的联创高管已悉数离职,王小川身后空无一人。

AI 智能体,现在有了专用的算力。

Reve 在 7 月 9 日把图像模型迭代到了 2.1 版。距离 2.0 发布刚好一个月,放在基础模型圈子这不算常见。前面只挡着一个 OpenAI 的 GPT Image 2。另外官方说:「训练这版模型用的算力不到排行榜前后邻居的十分之一」。
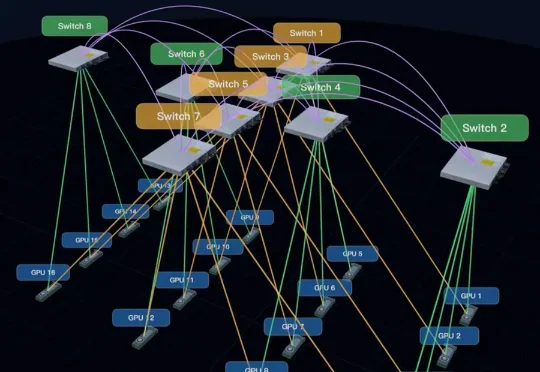
一家推翻传统网络架构的清华系创业公司,联合智谱、清华大学推出了全新的网络架构ZCube,能提升推理算力集群15%的Token产量,还能砍下约33%的网络硬件成本。近日,驭驯网络已完成智谱独家领投的数千万元融资,源合资本担任长期财务顾问。

37.7°C,干趴了一台国家级AI超算。6月底,英国遭遇有记录以来最热的六月。剑桥大学的Dawn——全英最快的AI超算之一——冷却系统当场热瘫,上千块GPU被迫休了一周多的高温假,350多个科研项目全线急刹。

7月10日,光合组织2026智能计算应用大会上,中科曙光掷地有声地抛出一个数字:十万。中国首个全国产十万卡AI超集群——曙光8000(登峰),正式落成,并依托国家超算互联网,火速接入全国一体化算力网。