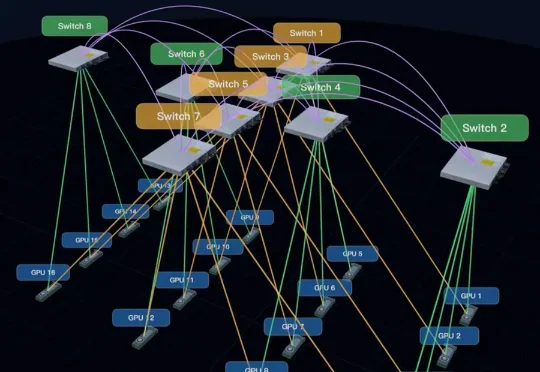
驭驯网络融资数千万,用ZCube重构AIDC网络基建,3个月拿下过亿订单
驭驯网络融资数千万,用ZCube重构AIDC网络基建,3个月拿下过亿订单一家推翻传统网络架构的清华系创业公司,联合智谱、清华大学推出了全新的网络架构ZCube,能提升推理算力集群15%的Token产量,还能砍下约33%的网络硬件成本。近日,驭驯网络已完成智谱独家领投的数千万元融资,源合资本担任长期财务顾问。
来自主题: AI资讯
8676 点击 2026-07-14 09:43
 搜索
搜索
一家推翻传统网络架构的清华系创业公司,联合智谱、清华大学推出了全新的网络架构ZCube,能提升推理算力集群15%的Token产量,还能砍下约33%的网络硬件成本。近日,驭驯网络已完成智谱独家领投的数千万元融资,源合资本担任长期财务顾问。

美团今日宣布开源万亿参数大模型LongCat-2.0,同步开放针对国产算力芯片深度优化的推理代码。该模型总参数达1.6万亿,平均激活约480亿参数,是业界首个在五万卡国产算力集群上完成全流程训练与推理的万亿参数模型。

近期,深圳河套学院(SLAI)AI训练平台项目团队,联合哈尔滨工业大学(深圳)、深圳大数据研究院、华为GTS(全球技术服务)团队与深智城AI算力平台,仅用1个月,共同基于昇腾910C国产算力集群实现DeepSeek-V4-Pro全参数续训练/SFT稳定运行,完成长稳训练1500+步,训练MFU超30%,关键训练算子效率提升14%。

日前,上海基流科技股份有限公司(下称:基流科技)正式向港交所递交招股书,冲击港股 “AI基础设施第一股”,独家保荐人为国泰海通。基流科技目前是中国规模最大的独立AI算力集群提供商。这家公司成立三年即冲刺IPO,以清北学霸为核心班底,3名执行董事都是“90后”——33岁的董事长胡效赫、35岁的联席董事长王旭阳、33岁的联席首席执行官谢文奇。
一边是 DeepSeek。2026 年 4 月 24 日,正式发布新一代模型DeepSeek-V4 系列预览版,并同步开源。另一边,美团闷声干了件大事——用全国产算力集群,训练出了万亿参数大模型 LongCat-2.0 系列预览版( LongCat-2.0-Preview )。

Yotta Data Services Pvt. 作为运营印度最大规模英伟达公司人工智能处理器集群的数据中心运营商,正寻求以约 40 亿美元估值进行新一轮融资,同时准备提交首次公开募股的招股说明书草案。

在万卡、十万卡的训练时代,算力不再是唯一的瓶颈,网络已成全新掣肘!当AI训练进入十万卡时代,InfiniBand竟突然翻红,重新被追捧了?

两人小团队,仅用两周就复刻了之前被硅谷夸疯的DeepSeek-OCR?? 复刻版名叫DeepOCR,还原了原版低token高压缩的核心优势,还在关键任务上追上了原版的表现。完全开源,而且无需依赖大规模的算力集群,在两张H200上就能完成训练。

继余承东三折叠手机发布会上亮相麒麟芯片后,AI算力芯片也有了最新进展。就在华为全联接大会上,轮值董事长徐直军,带来了全球最强算力超节点和集群!Atlas 950 SuperPoD和Atlas 960 SuperPoD超节点,分别支持8192及15488张昇腾卡。
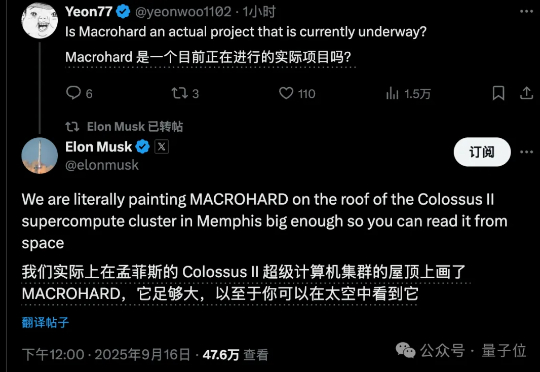
马斯克“巨硬计划”(MACROHARD)新动作曝光: 6个月从0建起算力集群,已完成200MW供电规模,足以支持11万台英伟达GB200 GPU NVL72。仅用6个时间,完成了OpenAI和甲骨文等合作花费15个月完成的工作,再次创造纪录。