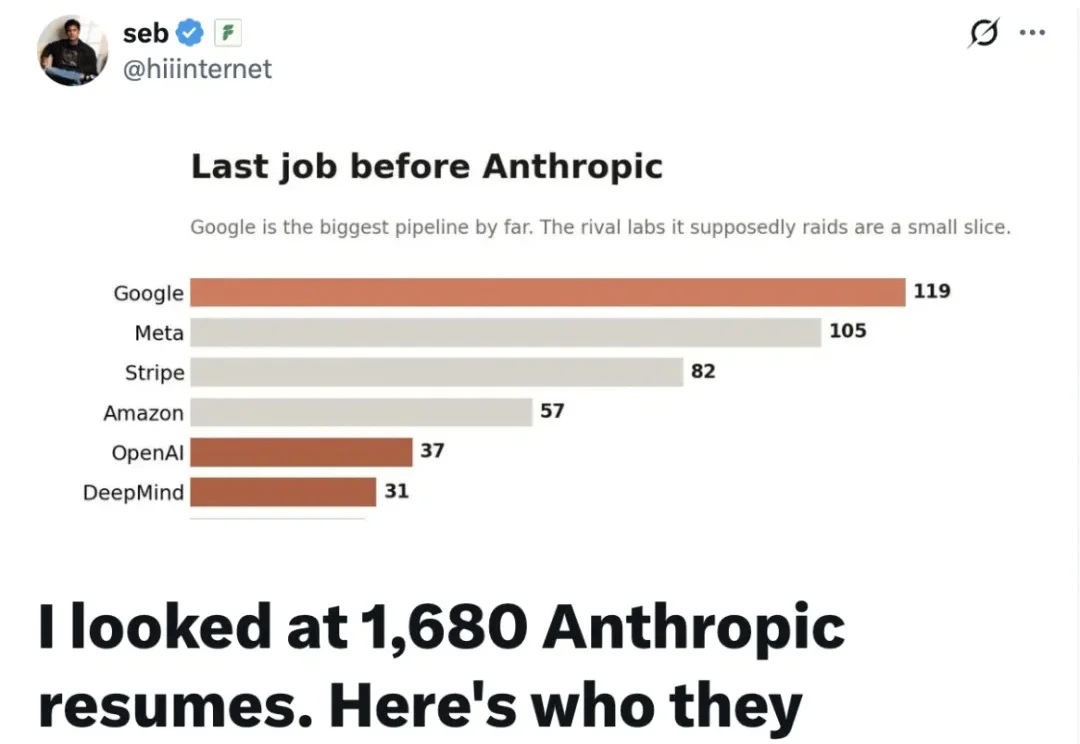
1680份员工履历揭开Anthropic招人底牌:「基础设施老兵」更吃香
1680份员工履历揭开Anthropic招人底牌:「基础设施老兵」更吃香当前,在狂热的 AI 浪潮下,大众对于头部 AI 大厂或明星初创公司往往有着一种带有光环的「刻板印象」:一定是由顶尖高校博士、各大优秀前沿研究论文的作者、算法天才等组成的团队。
来自主题: AI资讯
7501 点击 2026-06-16 10:21
 搜索
搜索
当前,在狂热的 AI 浪潮下,大众对于头部 AI 大厂或明星初创公司往往有着一种带有光环的「刻板印象」:一定是由顶尖高校博士、各大优秀前沿研究论文的作者、算法天才等组成的团队。

拆分后,字节仍将控股新公司,AI 制药核心团队、核心算法、技术平台和已有管线资产将整体进入新主体。

大模型开始进入理论计算机科学最核心的问题之一:算法设计。

数学,这块人类心智的荣耀,正面临一场前所未有的「降维打击」。当算法的「非人化」优势把80年的接力变成32小时的副产品时,我们不得不问:人类到底想要一个又一个正确答案,还是想要理解这些答案的过程?

几天前,OpenAI 用 AI 模型解决了一个关于点与点之间距离的数学问题,此前 80 年来这道题目一直未被完全攻克,消息一出一度被媒体刷屏。不过,没隔几天 16 位数学家站了出来,他们在荷兰莱顿大学发布了一份名为《莱顿宣言》的文件 [1]。
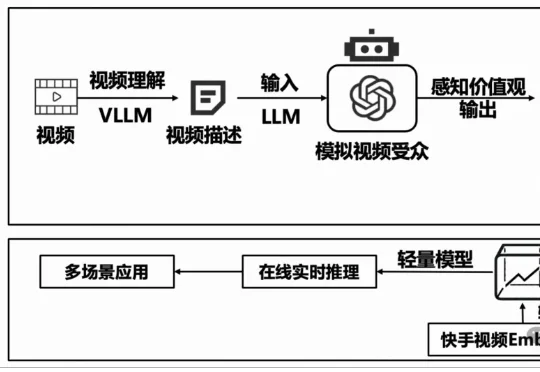
清华大学经济管理学院的陈柯均博士生、张佳音教授、徐心教授与快手消费策略算法部合作探索完成了一项联合实验:从视频传递的价值观的角度,去理解观看视频后用户的行为和心理变化。

Google DeepMind研究院姚顺宇最近接受媒体人采访时说:做一个好的产品经理,是一个我现在想不明白该怎么训练AI去做的事。言外之意,AI时代产品经理很难被替代。招聘市场已经给出了答案。根据脉脉2026年1—4月的数据,热招岗位里大模型算法排第一,产品经理排第二,AI产品经理也排到了前五的位置。

从数学、代码、复杂推理,到多轮工具调用,大模型的很多能力的提升都离不开 RL 后训练。但当模型规模进入 MoE 万亿参数级别之后,RL 不再只是一个算法问题,同时更加是一个系统问题。

刚刚完成新一轮亿元融资的具脑磐石,从成立之初押注的正是这个方向。具脑磐石由朱森华创立。他曾任华为云AI算法创新Lab主任,主导过AI脑科学云平台、盘古具身大模型、全球具身智能产业创新中心等系统级项目。在业内,他被称为“华为具身大脑一号位”。

5 月 20 日,武汉光谷。极佳视界(GigaAI)在「家庭场景子品牌发布会暨物理通用智能技术发布会」上,给出了一份相对完整的答案。这场发布会公布了五件事:全球首个物理 AGI「双金字塔」体系;家庭场景子品牌「拾光 SeeLight」与首款家庭通用人形机器人「拾光 S1」同步亮相;国内首个真实家庭场景百台部署落地武汉,Q3 起规模化运营;