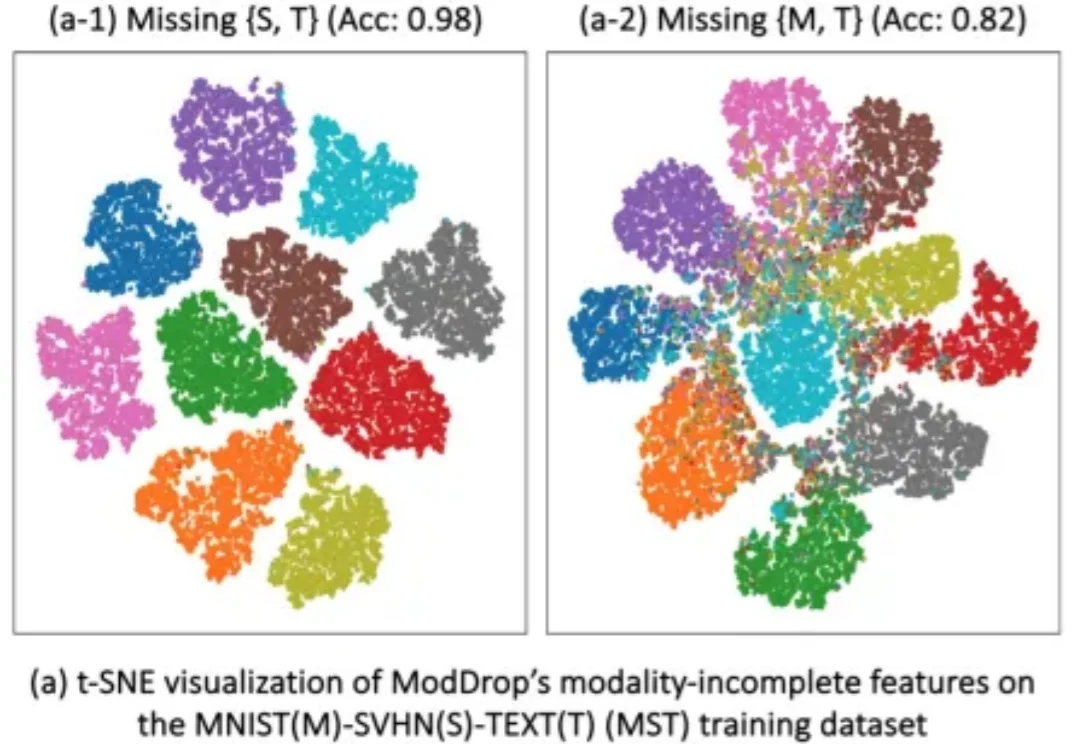
ICLR 2026 | 帝国理工大学提出DyMo:让多模态模型学会「选择」,突破模态缺失难题
ICLR 2026 | 帝国理工大学提出DyMo:让多模态模型学会「选择」,突破模态缺失难题多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。
来自主题: AI技术研报
9566 点击 2026-03-09 14:28
 搜索
搜索
多模态学习(Multimodal Learning)正在推动 AI 在医学影像、自动驾驶、人机交互等领域取得突破。通过融合图像、文本、表格等多种模态,模型能够获得更全面的信息,从而显著提升性能。
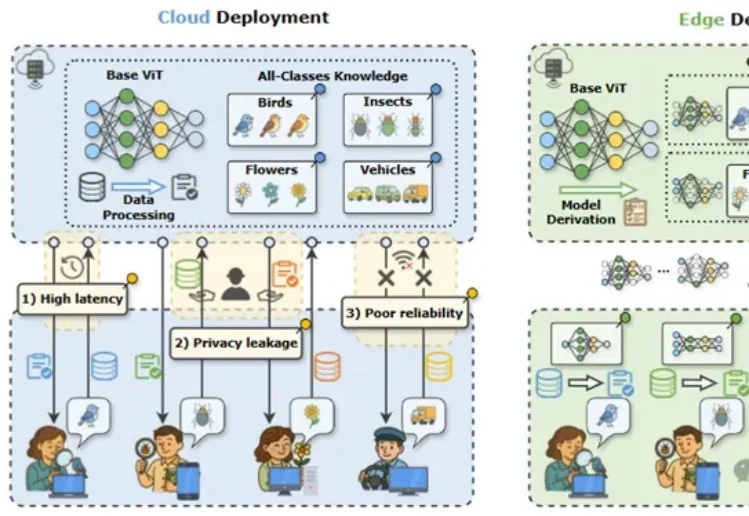
近年来,视觉大模型在自动驾驶、智慧医疗等场景中得到广泛应用,但在真实业务环境中,“大而全”的通用模型往往并不是最优选择。

自2011年成立九合创投,此后15年间,他带着团队坚持做科技领域的早期投资,陆续投了几十个智能化相关的项目——机器人软硬件通用底座提供商地瓜机器人、工业具身智能底座系统及基础设施墨影科技、陪伴机器人研发生产商赋之科技、外骨骼机器人科技公司傲鲨智能,以及自动驾驶领域独角兽Momenta,大模型智
由知名恋爱手游《奇点时代》研发商 CEO 张筱帆带头打造的 AI 男友「EVE」在年中释出 PV;明星创业者张月光打造的《星眠》也在年底透过内测首次与公众见面;我们还发现市值一度超过 180 亿美元的自动驾驶明星公司图森未来转也型做了 AI 陪伴产品「Breath of You」,尽管该产品目前已官宣停服。
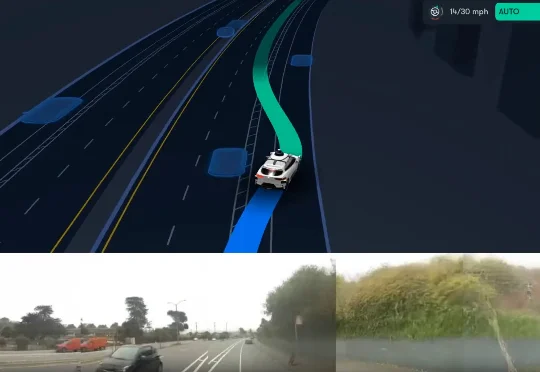
刚刚,Alphabet 旗下的自动驾驶汽车公司 Waymo,推出了最新世界模型 Waymo World Model,其基于 DeepMind 的 Genie 3 构建,在大规模、超真实自动驾驶仿真方面树立了全新的行业标杆。

Claude登陆火星!这是AI首次在外星上实现了「自动驾驶」。就在刚刚,NASA官方确认:人类历史上首次由AI全权规划的外星行驶任务,圆满完成!此次任务的具体地点在火星上的杰泽罗陨石坑(Jezero Crater)。
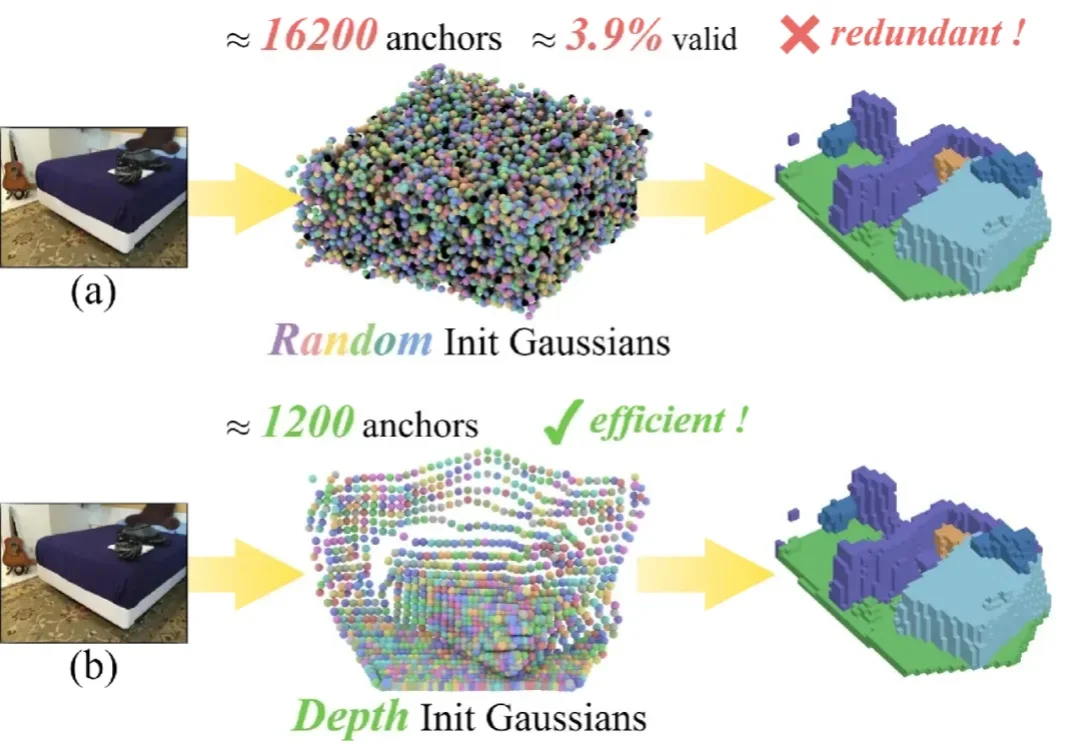
单目 3D 语义场景补全 (Semantic Scene Completion, SSC) 是具身智能与自动驾驶领域的一项核心技术,其目标是仅通过单幅图像预测出场景的密集几何结构与语义标签。

谷歌 DeepMind 发布 D4RT,彻底颠覆了动态 4D 重建范式。它抛弃了复杂的传统流水线,用一个统一的「时空查询」接口,同时搞定全像素追踪、深度估计与相机位姿。不仅精度屠榜,速度更比现有 SOTA 快出 300 倍。这是具身智能与自动驾驶以及 AR 的新基石,AI 终于能像人类一样,实时看懂这个流动的世界。
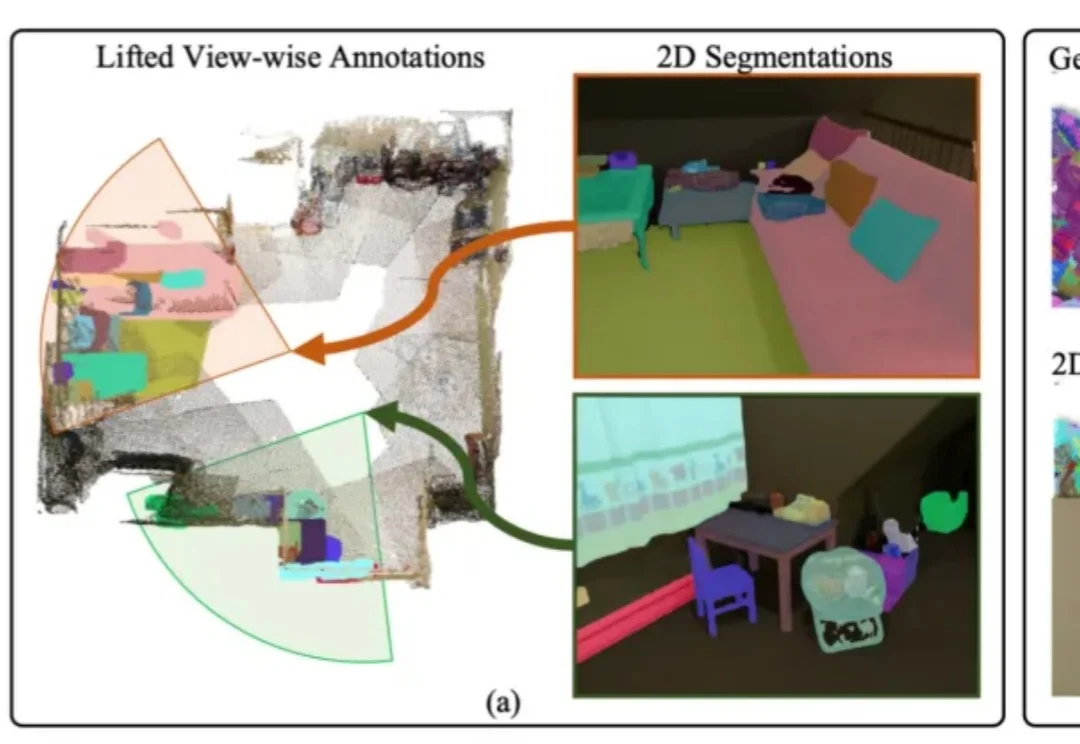
3D模型的实例分割一直受限于稀缺的训练数据与高昂的标注成本,训练效果有待提升。
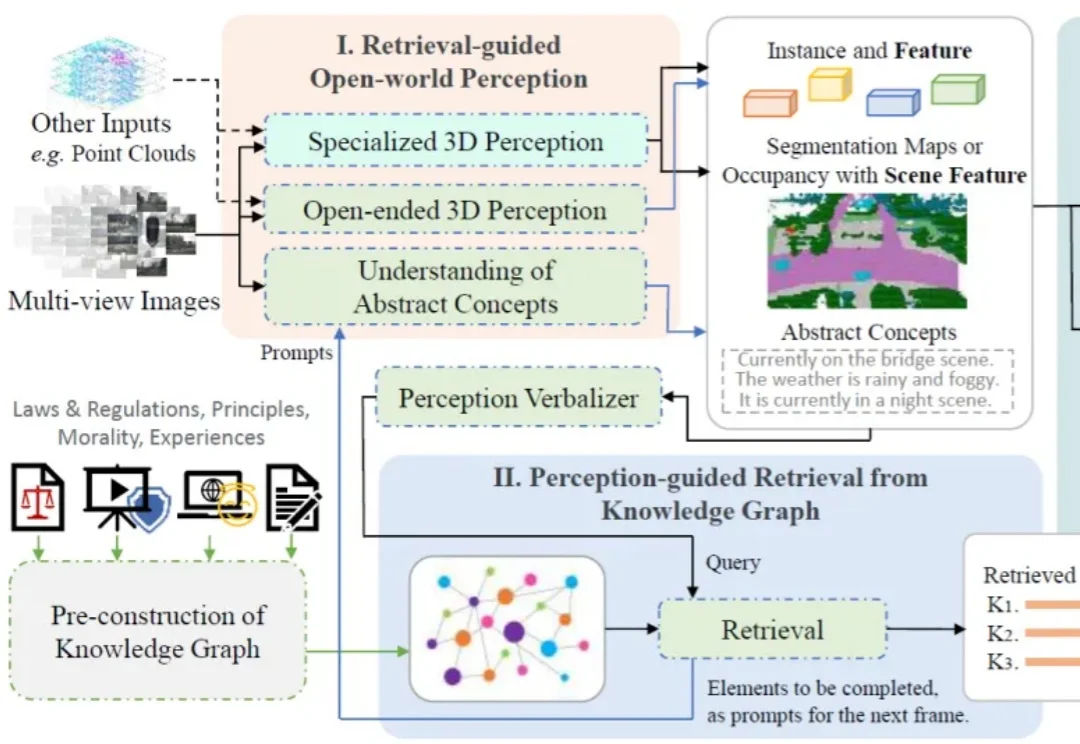
一个智能驾驶系统,在迈向高阶自动驾驶的过程中,应当具备何种能力?除了基础的感知、预测、规划、决策能力,如何对三维空间进行更深入的理解?如何具备包含法律法规、道德原则、防御性驾驶原则等知识?如何进行基本的视觉 - 语言推理?如何让智能系统具备世界观和价值观?