几千人催我蒸馏的X冷启动Skill,开源了!
几千人催我蒸馏的X冷启动Skill,开源了!大家好,我是袋鼠帝 几天前我尝试做了一个相对粗糙的视频,是关于我开源的仓颉Skill的 没想到居然爆火了!(全网将近50万播放)。
来自主题: AI技术研报
6374 点击 2026-07-16 10:11
 搜索
搜索
大家好,我是袋鼠帝 几天前我尝试做了一个相对粗糙的视频,是关于我开源的仓颉Skill的 没想到居然爆火了!(全网将近50万播放)。
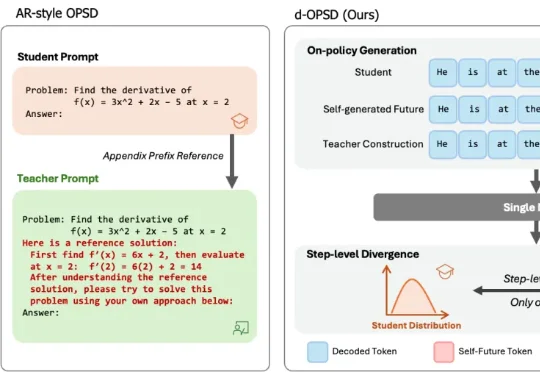
有没有一种更为合适的 OPSD 范式?近期,清华大学和马普所等机构的研究者们联合推出的 d-OPSD,给这一问题提供了完美的答案。这是第一个针对扩散大语言模型的 OPSD 范式,无需参考解,无需额外的教师模型,只需要 RL 十分之一的训练步数,便可以达到或超出 RL 的后训练效果。
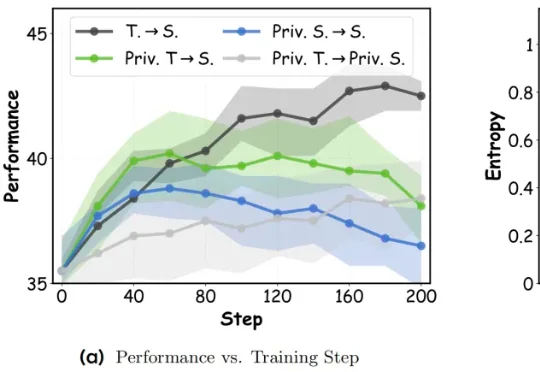
最近,来自新加坡国立大学、香港中文大学 MMLab、北京大学和京东探索研究院的研究团队提出了一种全新的在线策略蒸馏方法: DOPD (Dual On-policy Distillation) ,通过优势感知的双重蒸馏范式,成功破解了这一难题。
大家好,我是袋鼠帝。 没想到cangjie-skill在4月开源,中间没怎么推,两个月还慢慢涨到了1.3K Star,有点出乎我的意料。

据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。
Agent从来不是不会用浏览器,只是浪费太多时间在探索——BrowserBC把人类轨迹蒸馏成可复用Skill来完成Behavior Cloning,用户点一遍,Agent照着就能跑通。Einsia AI旗下Navers Lab发布的开源项目BrowserBC给出的答案,是一条三步范式:录制→转写成Skill→交付执行。

最近看到越来越多的一些国民级产品,开始把自己的一些能力,给封装称Skill或者MCP,来向大家开放,我觉得这个大家逐渐为Agent来做能力的趋势,越来越明显了。特别是前段时间瑞幸咖啡上线了AI开放平台,支持MCP、CLI、Skill三种接入方式。

难怪Meta CTO都不得不承认“内部士气快跌到历史谷底”了。围绕AI,小扎又整出了新的幺蛾子:之前不是说要把员工们全蒸馏了吗?这事紧急叫停了,因为数据搞!泄!露!啦!

Fable 5正在引发众多质疑:一声「你好」就能触发警报,一问高端技术就会被暗箱降智。Anthropic的安全承诺,正在变成一场开源圈愤怒的「安全谎言」。
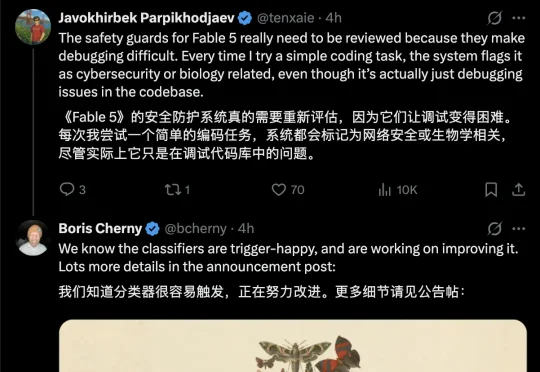
Claude刚刚发布的新模型Fable 5,很多人可能压根就用不上!有不少网友实测发现,Fable 5的安全护栏检测机制的触发几率似乎比官方宣称的不到5%严格得多。无论是普通编码任务。