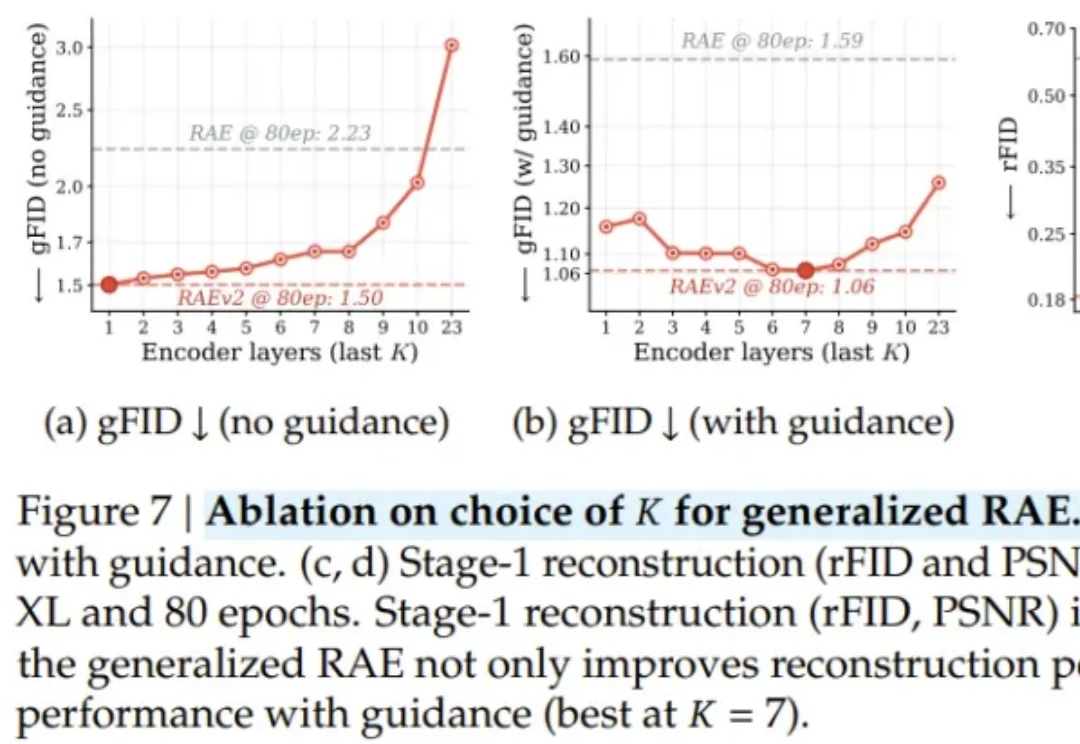
刚刚,谢赛宁团队放出第二代表征自编码器 RAEv2
刚刚,谢赛宁团队放出第二代表征自编码器 RAEv2AI 图像生成通常遵循「能力越强、代价越高」的铁律;与此同时,学界却在悄悄质疑另一个更根本的浪费:传统 VAE 对图像语义几乎一无所知,而 DINOv2、SigLIP 等视觉编码器早已从数亿张图片中习得了丰富的视觉常识。图像生成模型,真的需要从零开始「发明」对图像的理解吗?
来自主题: AI技术研报
8888 点击 2026-05-21 16:45
 搜索
搜索
AI 图像生成通常遵循「能力越强、代价越高」的铁律;与此同时,学界却在悄悄质疑另一个更根本的浪费:传统 VAE 对图像语义几乎一无所知,而 DINOv2、SigLIP 等视觉编码器早已从数亿张图片中习得了丰富的视觉常识。图像生成模型,真的需要从零开始「发明」对图像的理解吗?
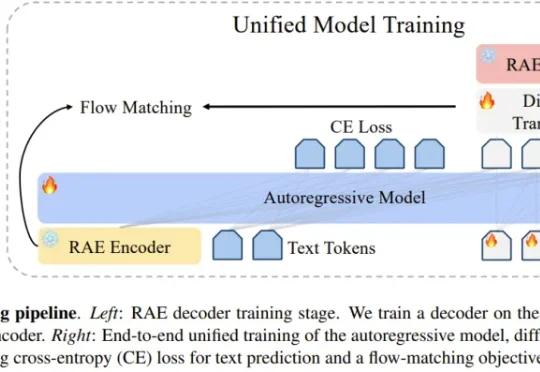
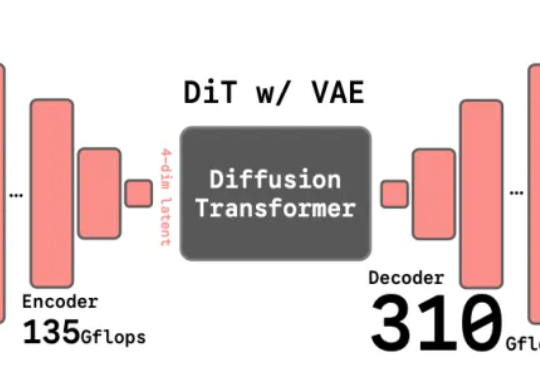
编辑|Panda 在文生图模型的技术版图中,VAE 几乎已经成为共识。从 Stable Diffusion 到 FLUX,再到一系列扩散 Transformer,主流路线高度一致:先用 VAE 压缩视
谢赛宁团队最新研究给出了答案——VAE的时代结束,RAE将接力前行。其中表征自编码器RAE(Representation Autoencoders)是一种用于扩散Transformer(DiT)训练的新型自动编码器,其核心设计是用预训练的表征编码器(如DINO、SigLIP、MAE 等)与训练后的轻量级解码器配对,从而替代传统扩散模型中依赖的VAE(变分自动编码器)。