
RL新思路!复旦用游戏增强VLM通用推理,性能匹敌几何数据
RL新思路!复旦用游戏增强VLM通用推理,性能匹敌几何数据复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。
来自主题: AI技术研报
9782 点击 2025-10-21 10:05
 搜索
搜索
复旦大学NLP实验室研发Game-RL,利用游戏丰富视觉元素和明确规则生成多模态可验证推理数据,通过强化训练提升视觉语言模型的推理能力。创新性地提出Code2Logic方法,系统化合成游戏任务数据,构建GameQA数据集,验证了游戏数据在复杂推理训练中的优势。
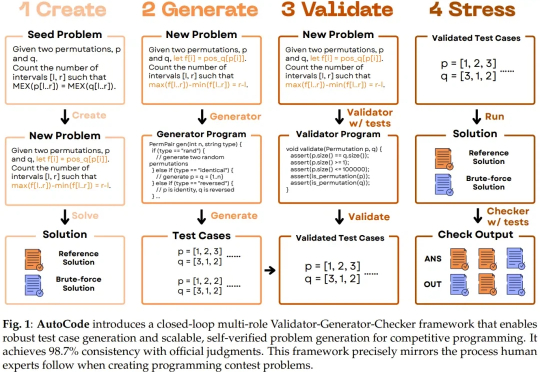
随着大型语言模型(LLM)朝着通用能力迈进,并以通用人工智能(AGI)为最终目标,测试其生成问题的能力也正变得越来越重要。尤其是在将 LLM 应用于高级编程任务时,因为未来 LLM 编程能力的发展和经济整合将需要大量的验证工作。
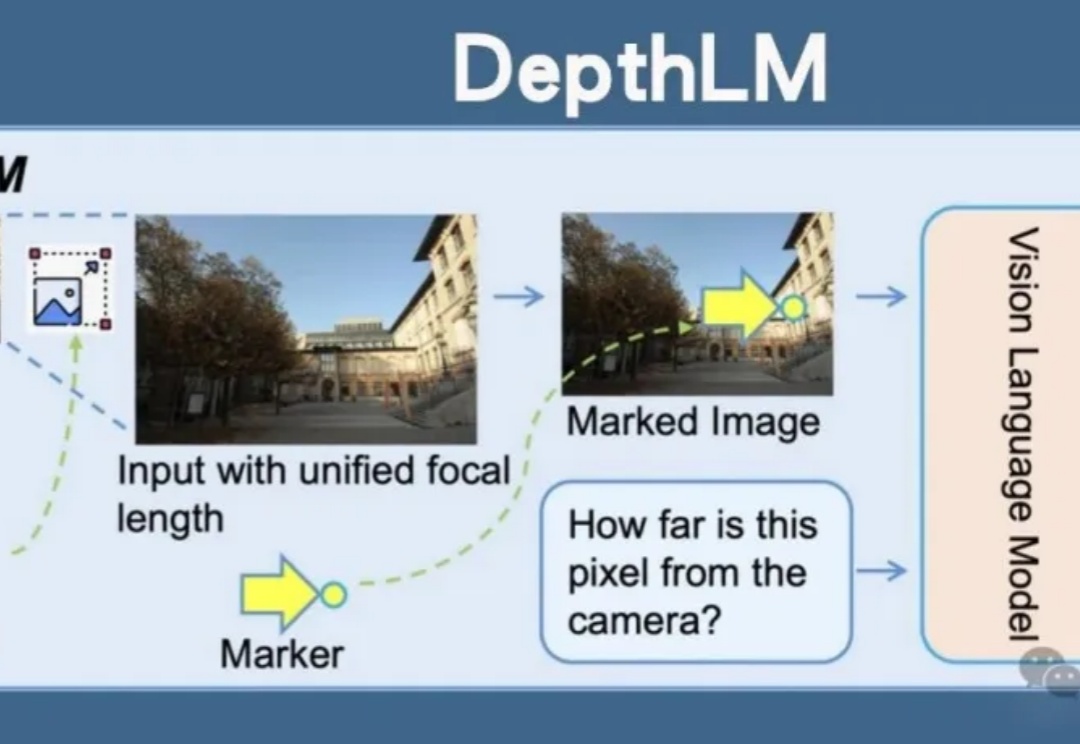
Meta开源DepthLM,首证视觉语言模型无需改架构即可媲美纯视觉模型的3D理解能力。通过视觉提示、稀疏标注等创新策略,DepthLM精准完成像素级深度估计等任务,解锁VLM多任务处理潜力,为自动驾驶、机器人等领域带来巨大前景。
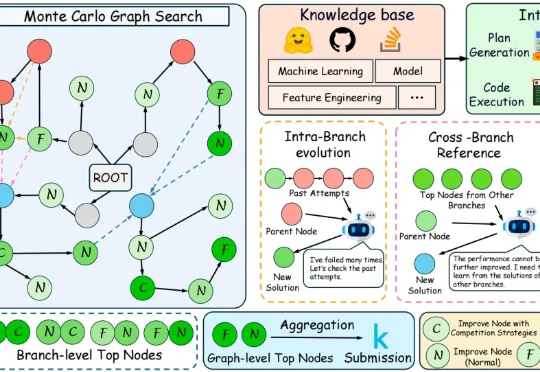
在代码层面,大语言模型已经能够写出正确而优雅的程序。但在机器学习工程场景中,它离真正“打赢比赛”仍有不小差距。
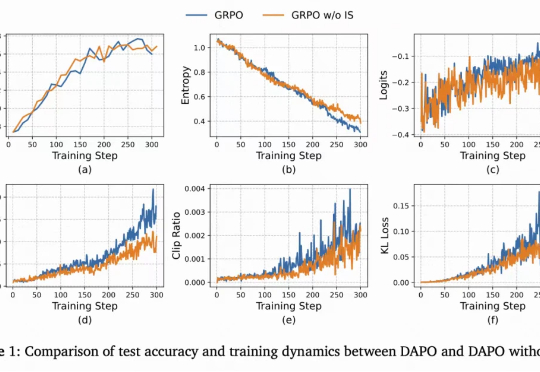
从ChatGPT到DeepSeek,强化学习(Reinforcement Learning, RL)已成为大语言模型(LLM)后训练的关键一环。
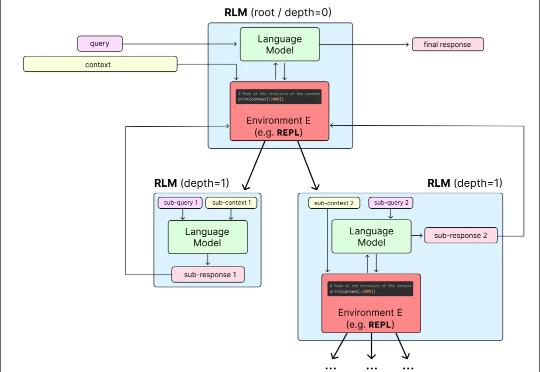
目前,所有主流 LLM 都有一个固定的上下文窗口(如 200k, 1M tokens)。一旦输入超过这个限制,模型就无法处理。 即使在窗口内,当上下文变得非常长时,模型的性能也会急剧下降,这种现象被称为「上下文腐烂」(Context Rot):模型会「忘记」开头的信息,或者整体推理能力下降。

近期,扩散语言模型备受瞩目,提供了一种不同于自回归模型的文本生成解决方案。为使模型能够在生成过程中持续修正与优化中间结果,西湖大学 MAPLE 实验室齐国君教授团队成功训练了具有「再掩码」能力的扩散语言模型(Remasking-enabled Diffusion Language Model, RemeDi 9B)。

近年来,多模态大语言模型(Multimodal Large Language Models, MLLMs)在图文理解、视觉问答等任务上取得了令人瞩目的进展。然而,当面对需要精细空间感知的任务 —— 比如目标检测、实例分割或指代表达理解时,现有模型却常常「力不从心」。

加州大学伯克利分校等机构的研究人员,近日推出了一种全新的基因组语言模型GPN-Star,可以将全基因组比对和物种树信息装进大模型,在人类基因变异预测方面达到了当前最先进的水平。
智东西10月15日报道,今日,阿里通义千问团队推出其最强视觉语言模型系列Qwen3-VL的4B与8B版本,两个尺寸均提供Instruct与Thinking版本,在几十项权威基准测评中超越Gemini 2.5 Flash Lite、GPT-5 Nano等同级别顶尖模型。