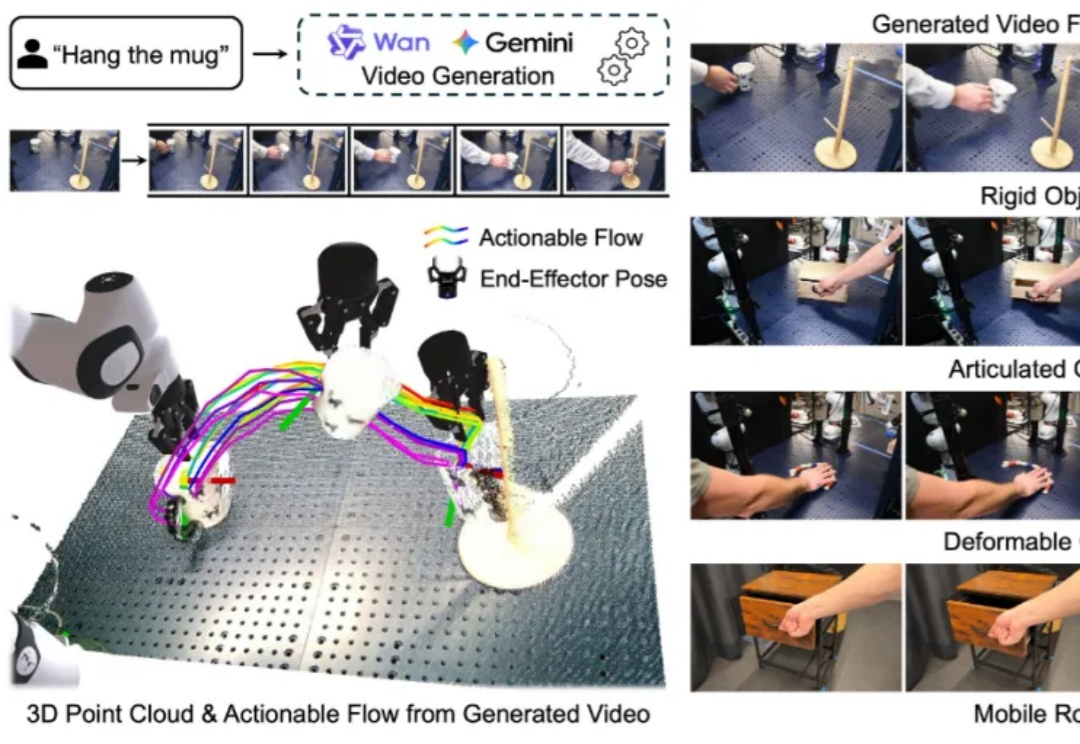
Qwen3 变身扩散语言模型?不从零训练也能跑,30B参数创纪录
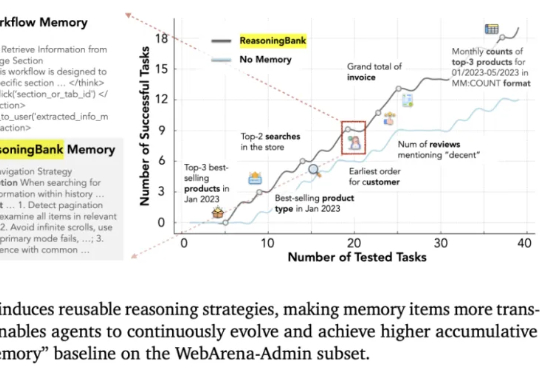
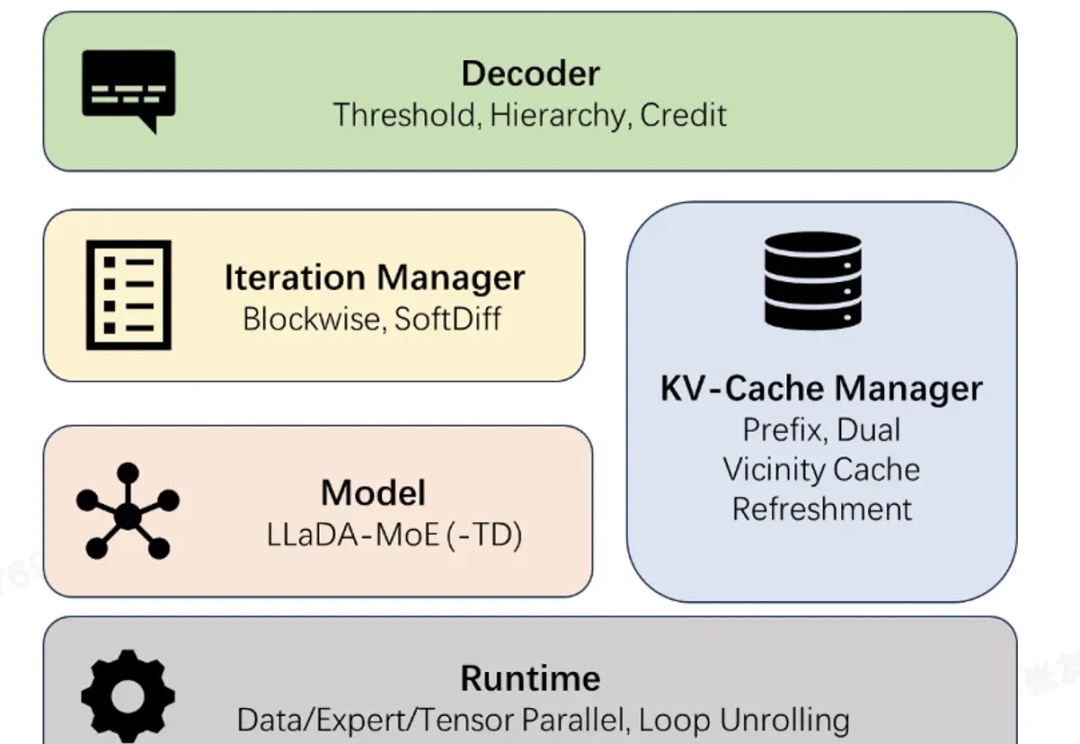
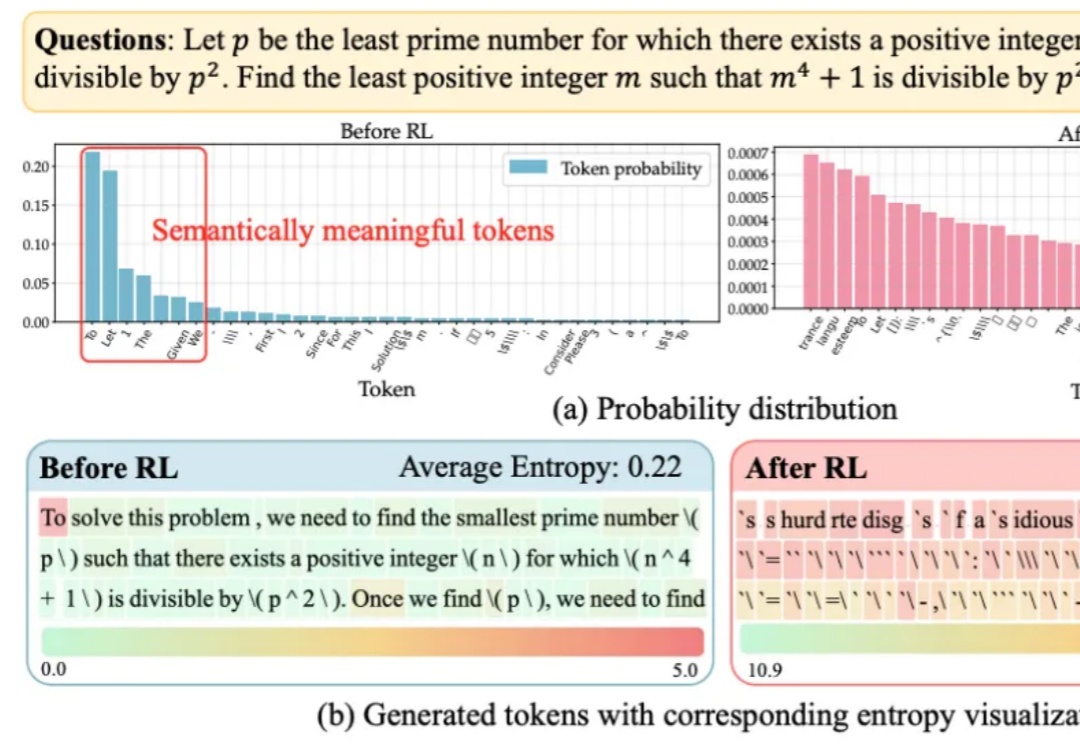
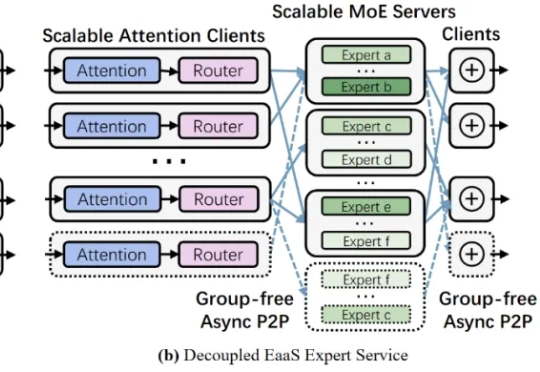
Qwen3 变身扩散语言模型?不从零训练也能跑,30B参数创纪录扩散语言模型(Diffusion Language Models,DLM)一直以来都令研究者颇感兴趣,因为与必须按从左到右顺序生成的自回归模型(Autoregressive, AR)不同,DLM 能实现并行生成,这在理论上可以实现更快的生成速度,也能让模型基于前后文更好地理解生成语境。
来自主题: AI技术研报
7664 点击 2025-10-15 14:00