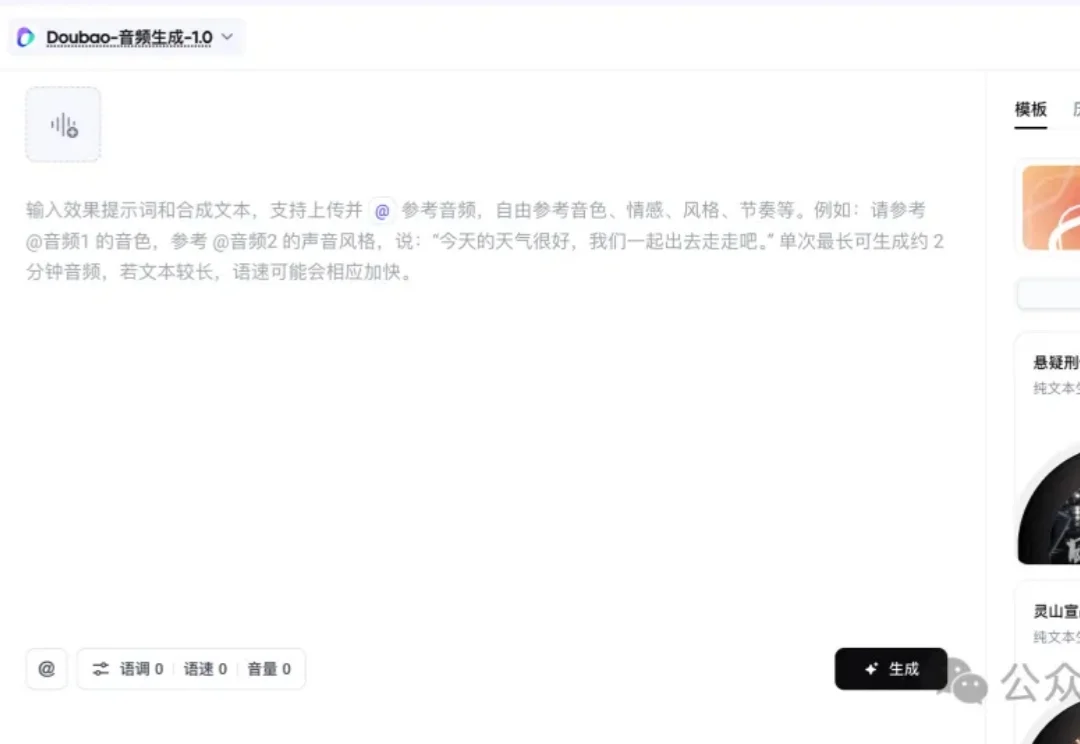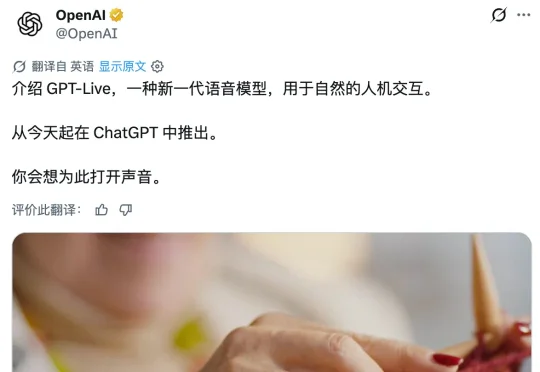
刚刚,ChatGPT 语音大升级,奥特曼:既神奇也真实
刚刚,ChatGPT 语音大升级,奥特曼:既神奇也真实就在刚刚,OpenAI 正式推出了全新一代语音模型 GPT-Live。正如它的名字一样,这一次,ChatGPT 的语音功能彻底「活」了过来。据官方透露,目前每周有超过 1.5 亿人使用 ChatGPT 的语音和听写功能来练习外语、讲睡前故事或在通勤时打发时间。而从今天起,这 1.5 亿人将迎来一次豆包式的进步:
来自主题: AI资讯
8306 点击 2026-07-09 09:50