
GenFlow4.0,让通用智能体走进办公现场
GenFlow4.0,让通用智能体走进办公现场昨天,我去了百度 AI DAY 现场。这次 AI DAY 的主角,是百度文库网盘联合推出的通用智能体GenFlow,正式升级到 4.0版本。GenFlow 4.0是一个「全端通用智能体」,给用户提供通用化、个性化、主动化的智能服务,月活已经破亿。现在还在网盘中兼容了OpenClaw的能力。
来自主题: AI资讯
8451 点击 2026-04-28 16:42
 搜索
搜索
昨天,我去了百度 AI DAY 现场。这次 AI DAY 的主角,是百度文库网盘联合推出的通用智能体GenFlow,正式升级到 4.0版本。GenFlow 4.0是一个「全端通用智能体」,给用户提供通用化、个性化、主动化的智能服务,月活已经破亿。现在还在网盘中兼容了OpenClaw的能力。
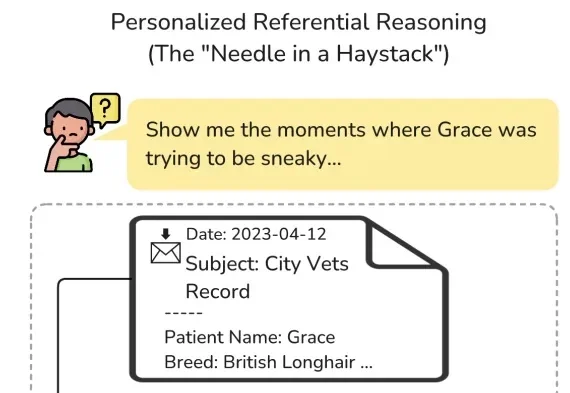
ATM-Bench 将「个人 AI 助手是否真的记得你」这件事,变成了一个研究的测试基准。结果并不乐观:专用记忆智能体系统普遍低于 20%,而 OpenClaw、Codex、Claude Code 等通用智能体普遍表现不佳,最高准确率不到 40%。
Codepilot 是藏师傅从今年一月开始纯 Vibe Coding 写个一个全平台通用开源 Agent 客户端。截止目前已经迭代了几百个版本,github 的 Star 也来到了 5100. 支持你能想到的小龙虾和 ClaudeCode 等 Agent 所有的能力,比如:
万亿级思考模型在开源!Ring-2.5-1T重磅出世,夺下IMO金牌。全新Ling 2.5架构,让它具备了深度思考、长程执行强大能力,真正进化为「通用智能体时代」的基座。

大模型的能力正在被不同的范式逐步解锁:In-Context Learning 展示了模型无需微调即可泛化到新任务;Chain-of-Thought 通过引导模型分步推理来提升复杂问题的求解能力;近期,智能体框架则赋予模型调用工具、多轮交互的能力。

近年来,以多智能体系统(MAS)为代表的研究取得了显著进展,在深度研究、编程辅助等复杂问题求解任务中展现出强大的能力。现有的多智能体框架通过多个角色明确、工具多样的智能体协作完成复杂任务,展现出明显的优势。
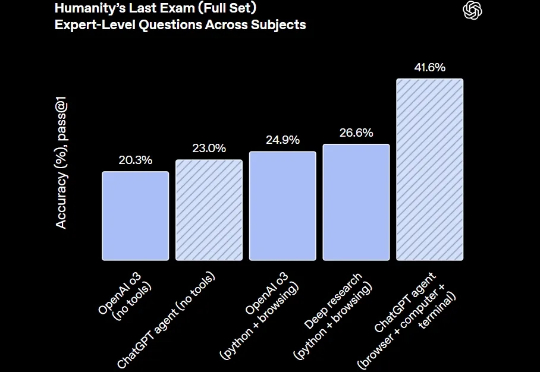
ChatGPT 现在可以思考行动,主动选择工具,用自己的虚拟计算机为你完成任务。 Agent AI 时代,比我们想象中来得要早一些。
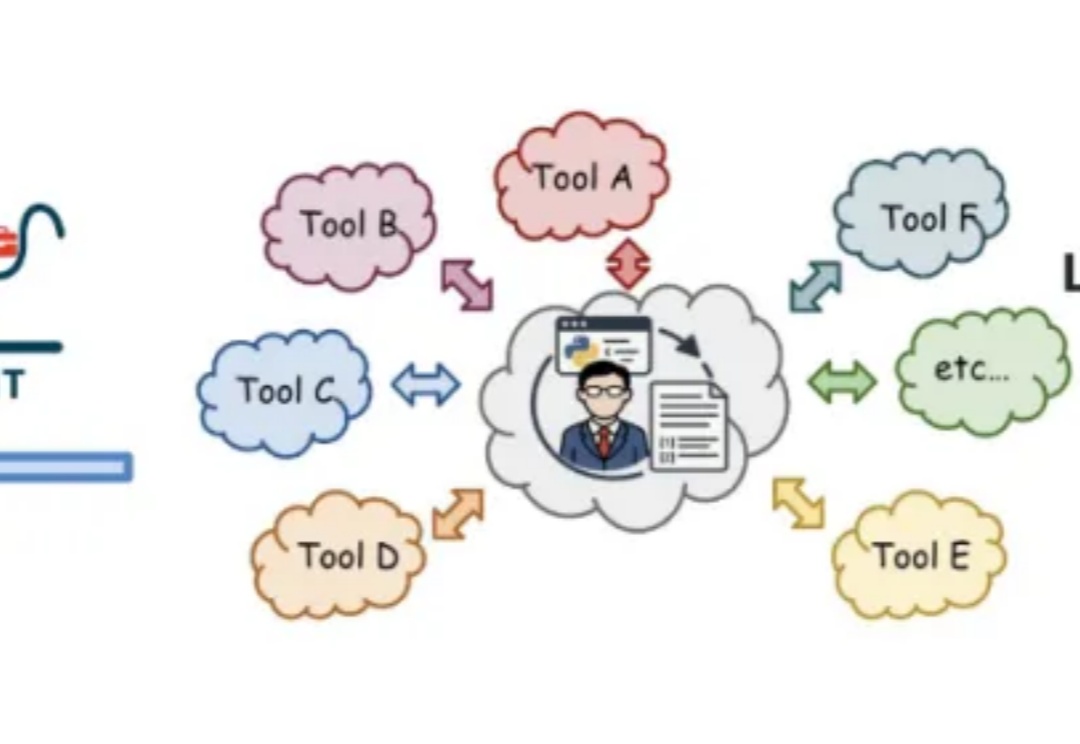
智能体技术日益发展,但现有的许多通用智能体仍然高度依赖于人工预定义好的工具库和工作流,这极大限制了其创造力、可扩展性与泛化能力。

开发能在开放世界中完成多样任务的通用智能体,是AI领域的核心挑战。开放世界强调环境的动态性及任务的非预设性,智能体必须具备真正的泛化能力才能稳健应对。然而,现有评测体系多受限于任务多样化不足、任务数量有限以及环境单一等因素,难以准确衡量智能体是否真正「理解」任务,或仅是「记住」了特定解法。
“首个通用智能体”Manus背后公司被曝正在硅谷寻求融资——以5亿美元估值,折合人民币37.5亿元,而距离它横空出世也不过才三周时间。从官方消息看,这几天他们确实也在硅谷面对面开用户聚会,据说是场场满员的那种。