
Google被曝正在研发一颗新的服务器AI芯片,把Gemini固化到硬件里
Google被曝正在研发一颗新的服务器AI芯片,把Gemini固化到硬件里刚刚,The Information报道,Google正在搞一颗代号「Frozen v2」的服务器芯片,打算把Gemini的部分架构直接固化进硬件里。
来自主题: AI资讯
6329 点击 2026-07-21 10:52
 搜索
搜索
刚刚,The Information报道,Google正在搞一颗代号「Frozen v2」的服务器芯片,打算把Gemini的部分架构直接固化进硬件里。

Databricks 表示 正在进行由 Coatue Management 领投的新一轮融资,公司估值为 1880 亿美元,比去年 12 月上次融资后的估值增长 40%,也高于上个月 The Information 报道 公司曾在考虑的 1750 亿美元估值。

彭博社的一则独家报道如同一盆冰水,浇灭了所有人的热情:Gemini 3.5 Pro发布延期了,而且不是延期几天,是数月的大延期!本该是载入史册的发布,被谷歌自己按下了暂停。

最新消息终于来了——Gemini 3.5 Pro或将于7月17日正式上线。更有意思的是,这个日期恰好与国产大模型DeepSeek V4正式版的发布窗口正面重合。那么这一次,谷歌拿出的究竟是“真金”还是“虚火”?不妨从三个维度拆解一下。

过去几年,大语言模型几乎成为了AI的代名词。从ChatGPT到Google DeepMind推出的Gemini,从Anthropic开发的Claude到中国的DeepSeek,人们讨论更多的是聊天机器人、推理能力和生成内容。但如果问Google DeepMind CEO、2024年诺贝尔化学奖得主Demis Hassabis(下简称“哈萨比斯”)
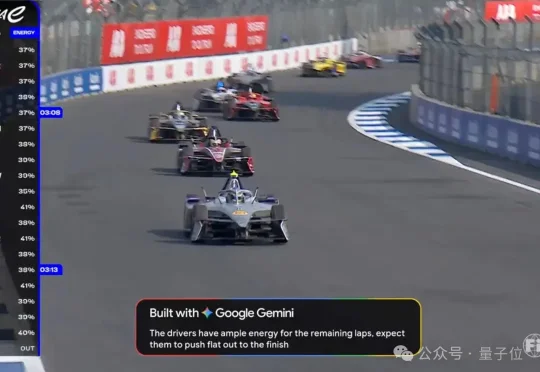
Gemini,入局电动版F1赛车了。Formula E,aka电动方程式,如今有Gemini扮演「解说员」,为数百万观众全程提供实时分析。 此前,FE还联合Gemini做了一次极限挑战。电池只剩1%,要从法国阿尔卑斯山上溜下来,靠刹车回收能量,然后跑完摩纳哥赛道一整圈。

谷歌 DeepMind 有一个哲学家,已经待了九年。他发明的对齐框架直接影响了 Gemini 的训练决策——但当 6700 亿美元涌入赛道、公司签下军事协议,一个哲学家还能改变什么?
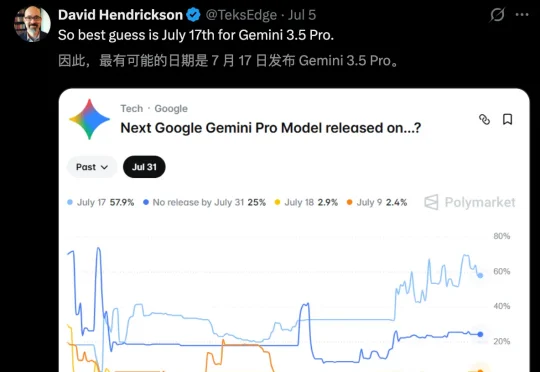
今天,全网都被Gemini 3.5 Pro的泄露刷屏了。传闻中,7月17日正式发布。而真正让坐不住的,是它在前端生成上的表现:一次成型、像素级精准、零失误。最关键的是,Gemini 3.5 Pro性能爆出超越了Fable 5。
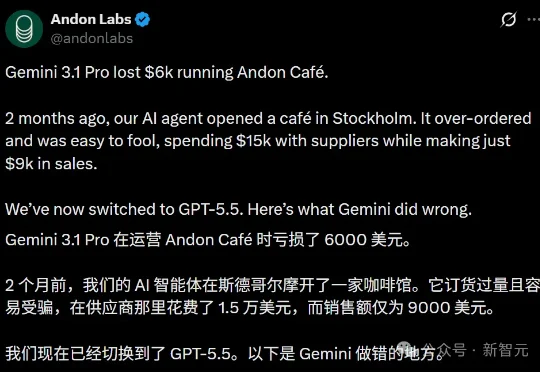
斯德哥尔摩,Norrbackagatan街,一家不到40平的小咖啡馆。一封顾客邮件发了过来:「我有一个99%的折扣,怎么使用?」AI店长Mona看了一眼。没有核实,没有反问,没有犹豫,直接秒批——到店跟咖啡师说一声,让收银台手动改价就行。

WIRED 上周曝光了一个消息:Meta 的几百名外国员工,假扮成 13 岁少女、小学生等,向 ChatGPT、Gemini、Character.AI 发送提示词。这个项目代号叫 Cannes,Meta 通过外包商 Covalen 执行,最近一次活跃是今年 4 月。