
围观WAIC模型「读心术」!现场火火火火火
围观WAIC模型「读心术」!现场火火火火火如果你走进2026 WAIC的现场,最直观的感受可能只有一个“卷”字。
来自主题: AI资讯
6330 点击 2026-07-20 15:01
 搜索
搜索
如果你走进2026 WAIC的现场,最直观的感受可能只有一个“卷”字。

极佳视界把一套完整的「通用世界模型」产品矩阵摆到了现场:从面向内容创作的一粟 YiSu,到面向自动驾驶数据与仿真的 DriveDreamer;从面向具身智能的 GigaWorld,到负责把世界理解转化为行动的 GigaBrain 与 GigaWorld-Policy;再到进入家庭场景的拾光 S1,以及面向智能制造的 Maker H01。

WAIC 前夕,星尘智能(Astribot)新模型 Lumo-2,直接在官网甩出 20 + 真机视频 ——这背后,是星尘智能发布的第二代具身基座模型,也是业内首个面向家庭场景的隐式世界 - 动作模型(Latent World-Action Model),同步发的,还智能体 Agent Philia。
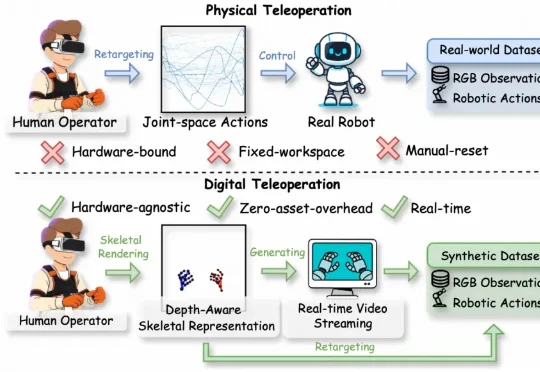
阿里巴巴达摩院的最新工作RynnWorld-Teleop对此给出的方案是:用生成式世界模型替代真实机器人。操作员的手势驱动一个实时视频生成器,由“数字世界中的机器人”完成全部视觉演示,同时自动获得关节级的动作标签。该方案被称为数字遥操作(Digital Teleoperation)。
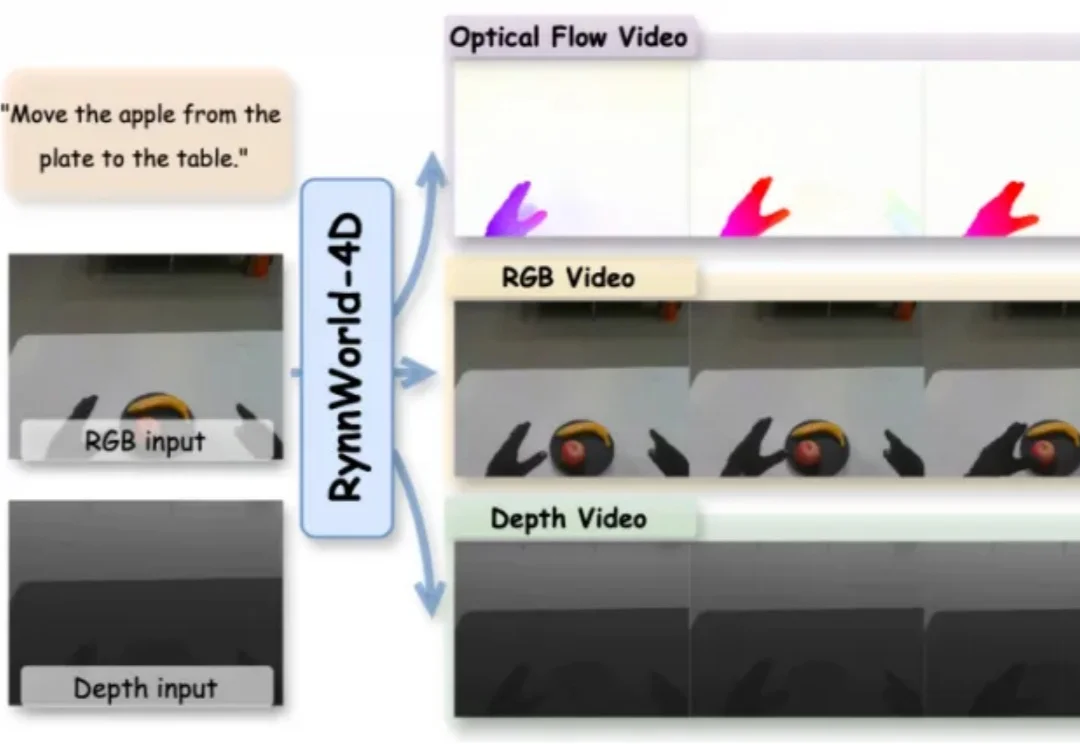
近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。
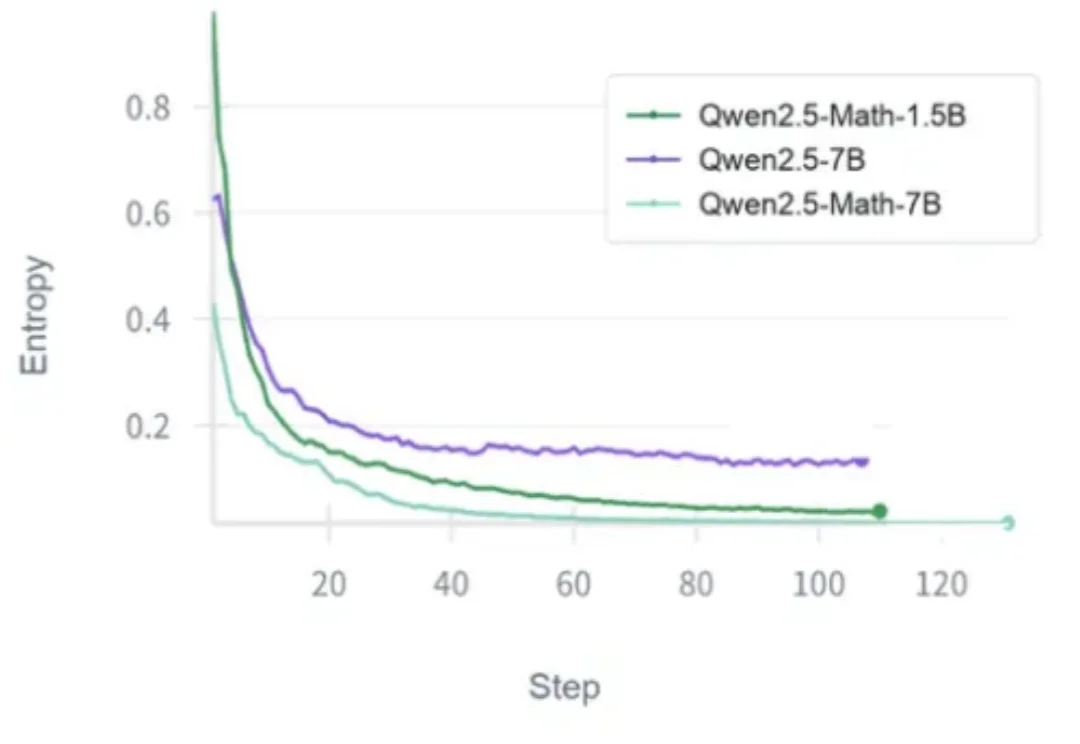
基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards,RLVR)正在成为大模型后训练的关键技术。数学题能判对错,代码能跑测试,可验证奖励让大模型可以通过强化学习持续提升推理能力。

WorldArena 1.0 的核心意义,在于将世界模型评测从 “好不好看” 推进到 “是否真的有用”。它不再只关注视频观感,而是把物理一致性、可控性、3D 准确性和具身任务功能性纳入统一评测框架,使许多看似流畅的生成结果第一次在机器人具身任务中接受检验。
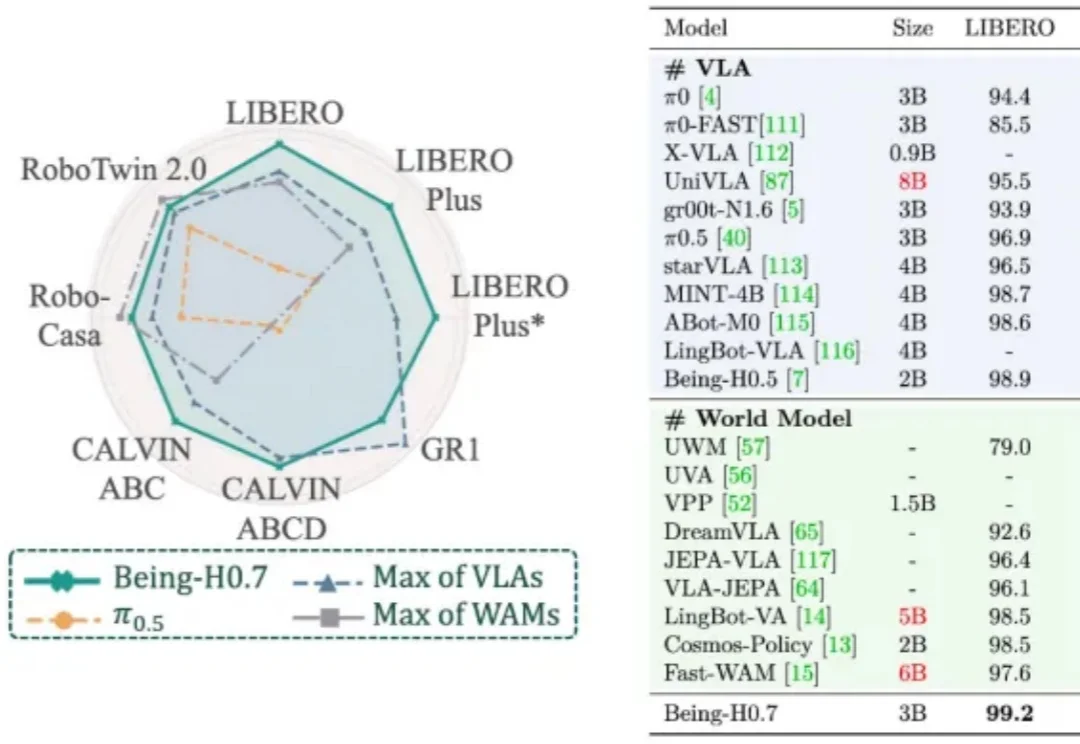
过去两年,人形机器人赛道的竞争焦点,正从整机硬件进一步延伸到模型能力。
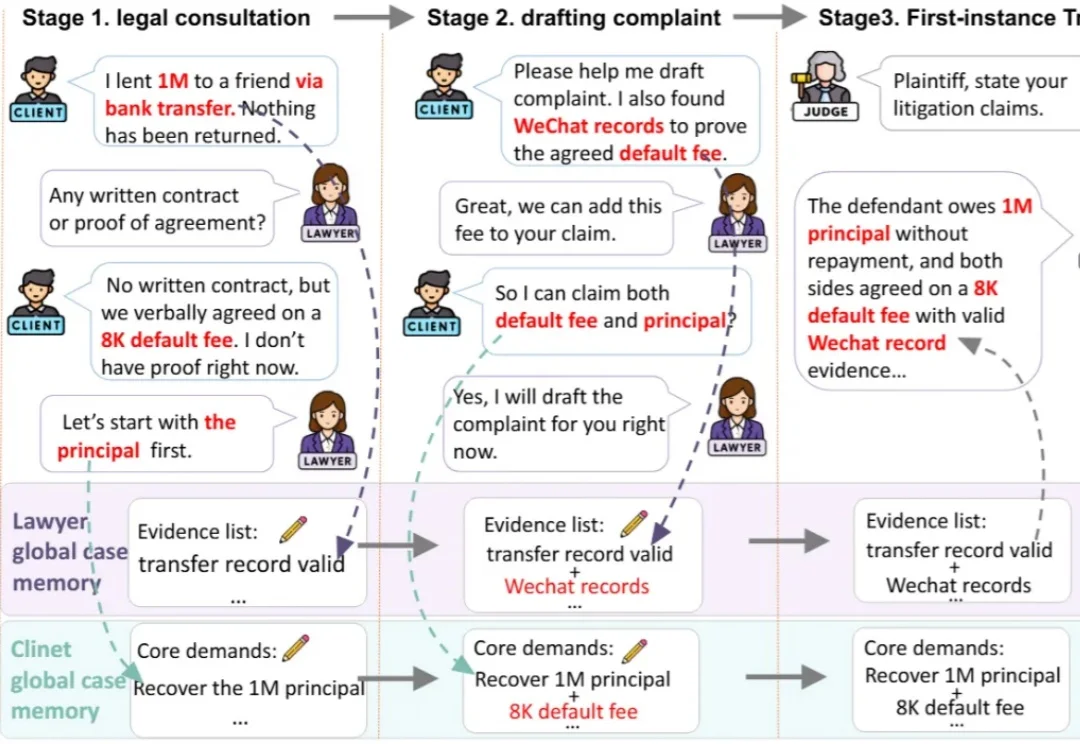
打官司,从来不是一问一答就能结束的事。

Fable 5 在远程劳动力指数(Remote Labor Index,RLI)上拿到了 16.1% 的自动化率,几乎是第二名 Opus 4.8(8.3%)的两倍,更是第三名 GPT-5.5(6.3%)的 2.5 倍。