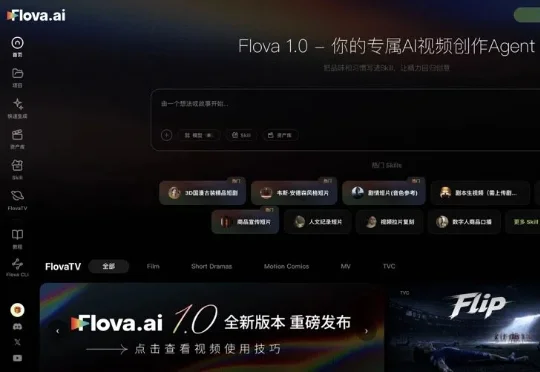
独家对话 Flova :脸萌、剪映后郭列再创业,做视频 Agent、但学的是 Claude Code
独家对话 Flova :脸萌、剪映后郭列再创业,做视频 Agent、但学的是 Claude CodeFlova 很受关注,融资是一方面,两轮融资,红杉、IDG 和云九资本投资,累计超 8000 万美元,据说是目前视频 Agent 产品的最大融资。而更主要的原因,可能是创始人郭列。郭列 2013 年做出脸萌,之后是 FaceU 激萌,2018 年被字节跳动以 3 亿美金并购,随后在字节孵化了轻颜相机、剪映和醒图。2025 年创业做 Flova,入局视频 Agent 赛道。
来自主题: AI资讯
8450 点击 2026-07-21 17:30