
鸿蒙为何选中一家世界模型「狂想者」?拆解极顶数创的AI 3D底牌
鸿蒙为何选中一家世界模型「狂想者」?拆解极顶数创的AI 3D底牌在传统认知里,制作一个高质量 3D 模型,往往意味着复杂的软件流程、昂贵的硬件设备,以及经年累月积累的专业知识。对专业设计师而言,这是日常工作;可对普通用户而言,却是「看得见,做不了」的高门槛。
来自主题: AI资讯
6937 点击 2026-07-14 16:12
 搜索
搜索
在传统认知里,制作一个高质量 3D 模型,往往意味着复杂的软件流程、昂贵的硬件设备,以及经年累月积累的专业知识。对专业设计师而言,这是日常工作;可对普通用户而言,却是「看得见,做不了」的高门槛。

不教AI认手,而是从视频世界模型里直接「读」出双手:三大基准SOTA,让百万小时野生视频第一次能变成机器人的操作教材。

近期,围绕「世界模型」的讨论持续升温。机器人、自动驾驶、视频生成、具身智能等多个方向都在频繁使用这一概念,相关系统不断出现,演示形式日益丰富,评价指标也越来越多。伴随这一趋势,一个基础问题变得格外重要:当一个模型被称为「世界模型」时,人们究竟在评价什么?
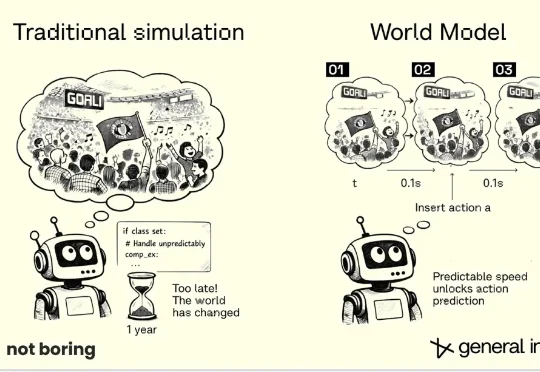
我们汇总了两篇文章的要点,想要讲清楚几件事:到底什么是世界模型?什么不是?当下的竞争格局:世界模型将走向何方,哪条路线可能胜出?所有路线都会撞上的那堵墙是什么,有哪些可能的解法?
蚂蚁集团旗下具身智能公司蚂蚁灵波,把这块最难的拼图拍上了桌:LingBot-VA 2.0——行业第一个具身原生预训练模型。所谓「具身原生」,一句话说清楚:不是拿现成的数字世界模型做嫁接,而是从数据、训练目标到模型架构,每一层都为「机器人在物理世界干活」而生—
最新世界模型 LingBot-World 2.0 正在试图实现的事情。「一个世界只需要几秒钟就能造出来」不再仅限于预制的世界,而是让每一次生成,都是一次全新的创造。这是一个秒级生成、支持实时交互的开源世界模型。
智源研究院悟界·RoboBrain Orca Team发布的技术报告Orca: The World is in Your Mind,想探索的正是这个问题。也有评论认为,Orca更接近早期通用世界模型的形态,即先学习世界如何变化,再将这种世界表征读出到理解、预测和行动任务中。
专注于4D世界模型研发和产业化的魔芯科技联合浙江大学潘云鹤院士团队发布MoWorld——全球首个Flash World Model,也是首个全栈基于国产NPU构建的实时交互世界模型。

以 LeWorldModel(LeWM)为例,它在规划时有一个重要瓶颈:每评估一条候选动作序列,模型都要一步步自回归 rollout。也就是说,LeWM 先预测下一步 latent,再把预测出的 latent 输入 dynamics model,继续预测下一步:

近日,通用世界模型领军企业生数科技完成新一轮5亿美金融资,创下国内通用世界模型领域最大单笔融资纪录,为企业技术研发与商业化落地注入强劲资本动能。本轮融资由阿里云领投,多家战略机构及老股东持续加码,巨头产业资本加持,凸显市场对其技术壁垒与商业化潜力的高度认可。