
刚刚,全球首台「真·Agent原生手机」STEPX Neo来了!
刚刚,全球首台「真·Agent原生手机」STEPX Neo来了!就在今天,阶跃星辰在发布会上一口气抛出三样东西——全球首个大模型原生AI终端品牌STEPX;全球首个智能体原生操作系统Step AOS;全球首款大模型原生智能体手机STEPX Neo。
来自主题: AI资讯
8982 点击 2026-07-13 21:01
 搜索
搜索
就在今天,阶跃星辰在发布会上一口气抛出三样东西——全球首个大模型原生AI终端品牌STEPX;全球首个智能体原生操作系统Step AOS;全球首款大模型原生智能体手机STEPX Neo。
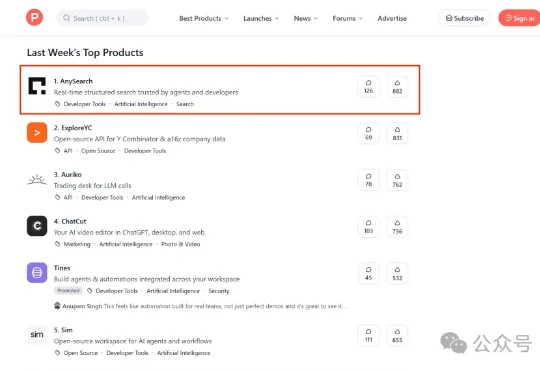
本期Product Hunt周榜Top 1出自中国团队,AnySearch——一款AI搜索产品。过去一年,PH榜一的位置被Agent、AI IDE、大模型轮番占据,几乎没见过搜索类产品的影子。就是因为在全球开发者眼里,普通AI搜索已经很难突围了。
这家名为 PrismML 的初创公司表示,已将 Qwen 3.6 缩减至可在 iPhone 17 Pro 上运行,该模型拥有 270 亿参数(参数大致类似于大脑中的突触,能够帮助决定模型可处理数据的复杂性)。相比之下,大多数在手机上运行的模型一次仅有几十亿个参数处于活动状态。

不教AI认手,而是从视频世界模型里直接「读」出双手:三大基准SOTA,让百万小时野生视频第一次能变成机器人的操作教材。
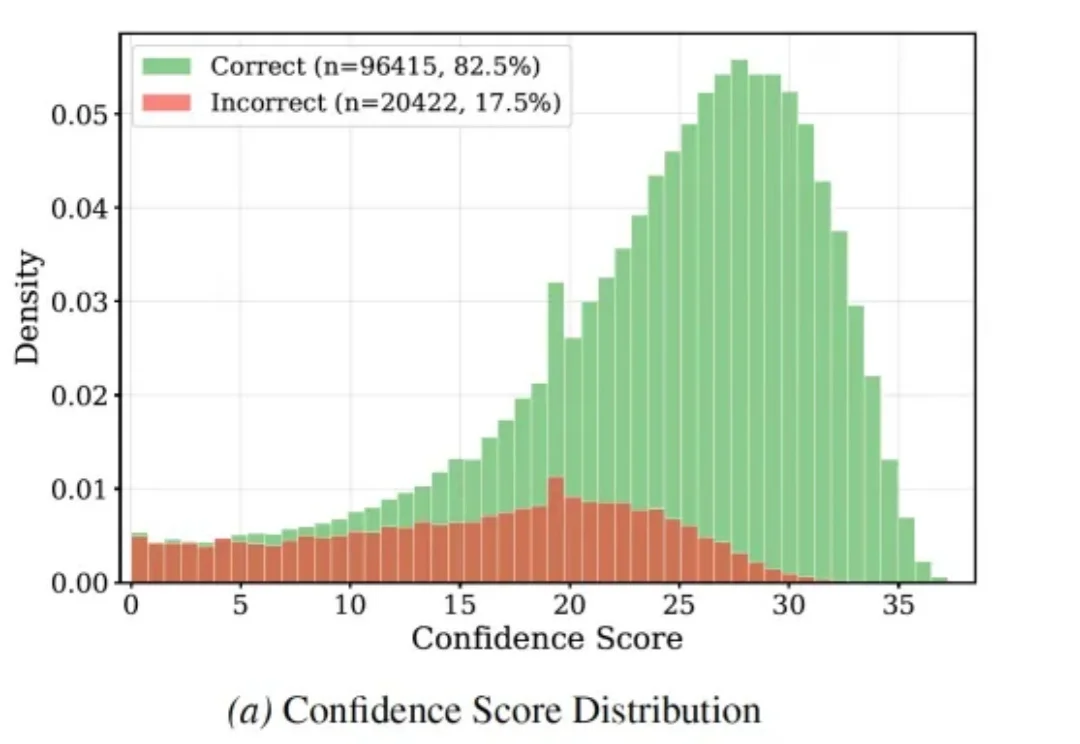
奖励模型(Reward Model, RM)是大语言模型对齐的核心组件,负责为模型输出提供符合人类偏好的评价信号。现有方法各有短板:标量判别式 RM 高效稳定但可解释性有限;生成式 judge 能给出判断理由,却需为每个样本生成长 reasoning,token 与延迟开销显著。

近期,围绕「世界模型」的讨论持续升温。机器人、自动驾驶、视频生成、具身智能等多个方向都在频繁使用这一概念,相关系统不断出现,演示形式日益丰富,评价指标也越来越多。伴随这一趋势,一个基础问题变得格外重要:当一个模型被称为「世界模型」时,人们究竟在评价什么?
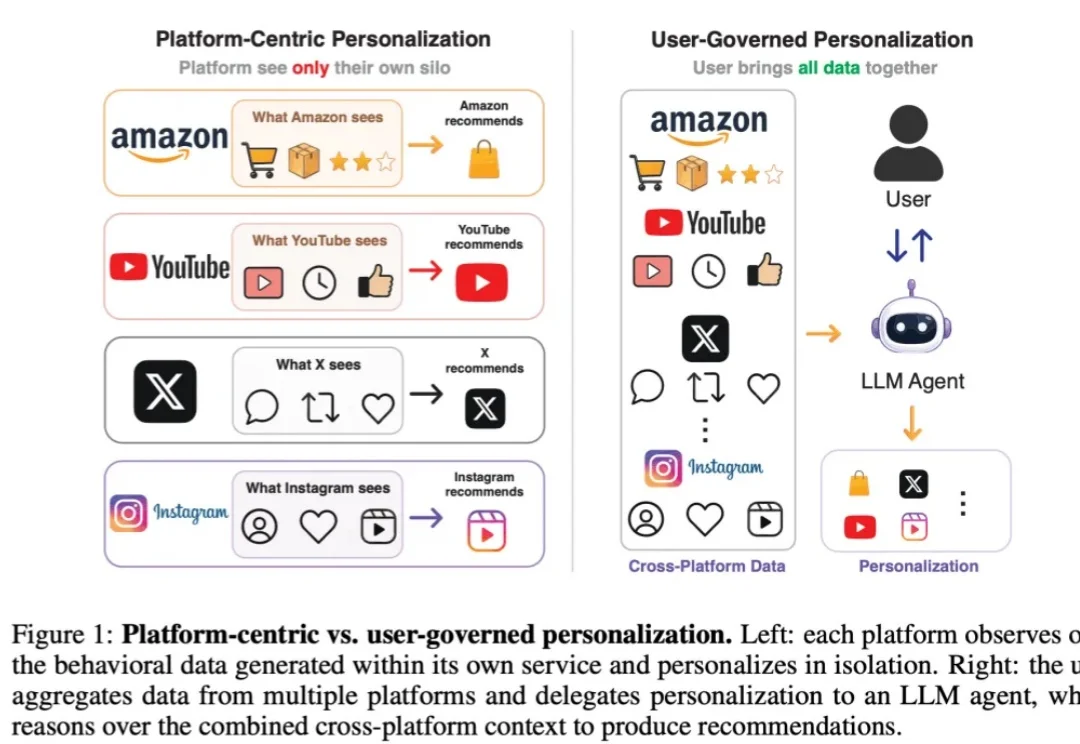
在过去二三十年的互联网发展中,个性化推荐几乎一直是平台的核心能力之一。打开视频 app,平台决定你接下来会刷到什么视频;打开购物软件,平台预测你可能会购买什么商品;打开短视频 app,平台根据你的浏览、点赞、停留和互动,不断优化信息流。某种意义上,现代互联网的用户体验本身就是由推荐系统塑造的。
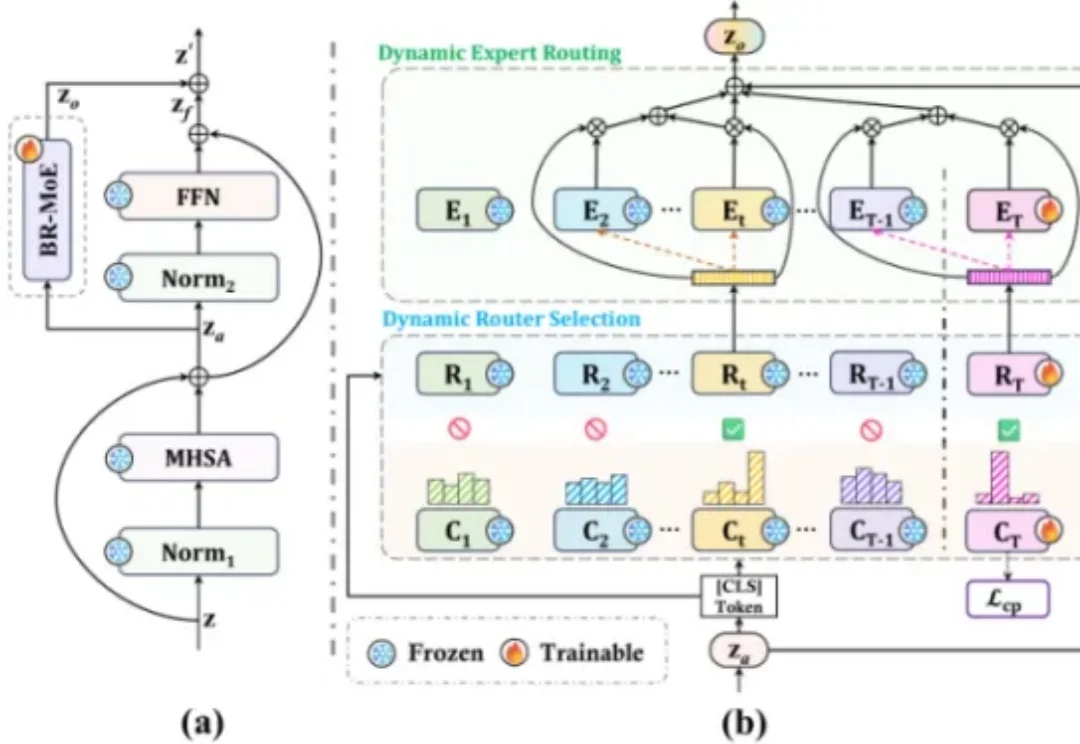
人类可以在一生中持续学习新知识,而不会轻易遗忘已有技能。然而对 AI 模型而言,这恰恰是一道极具挑战性的难题:每当模型学习新任务时,参数更新往往会覆盖历史知识,产生经典的 “灾难性遗忘” 难题。持续学习(Continual Learning)正是为突破这一瓶颈而生的研究方向。

过去几年,大语言模型几乎成为了AI的代名词。从ChatGPT到Google DeepMind推出的Gemini,从Anthropic开发的Claude到中国的DeepSeek,人们讨论更多的是聊天机器人、推理能力和生成内容。但如果问Google DeepMind CEO、2024年诺贝尔化学奖得主Demis Hassabis(下简称“哈萨比斯”)
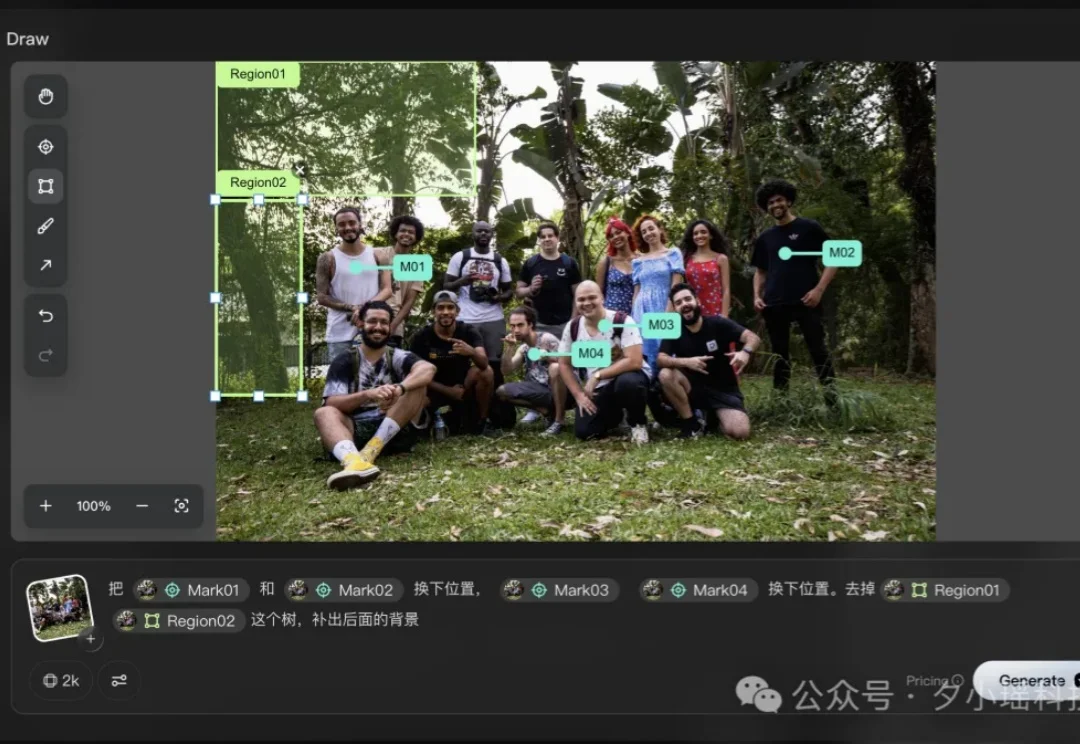
用 AI 生图的人,应该都体会过这种痛苦。