
这家六小龙上新全家桶,Agent接管终端关键一战!老黄预言时代来了
这家六小龙上新全家桶,Agent接管终端关键一战!老黄预言时代来了AI岂能只活在云端?刚刚,阶跃星辰上新来Step Edge 端侧模型全家桶!这次,AI能听懂语音、看懂屏幕,直接补齐了Agent本地执行的关键拼图。「端云协同」发力,你的手机与车机即将被彻底重构!
来自主题: AI资讯
9522 点击 2026-07-13 09:45
 搜索
搜索
AI岂能只活在云端?刚刚,阶跃星辰上新来Step Edge 端侧模型全家桶!这次,AI能听懂语音、看懂屏幕,直接补齐了Agent本地执行的关键拼图。「端云协同」发力,你的手机与车机即将被彻底重构!

2026年,AI安全终于被推到了台前。

近期,美国俄勒冈州立大学研发出一种新型成像传感器,不仅可在探测光线的同时进行图像存储(近期光照信息),还能实现信息的按需“遗忘”。
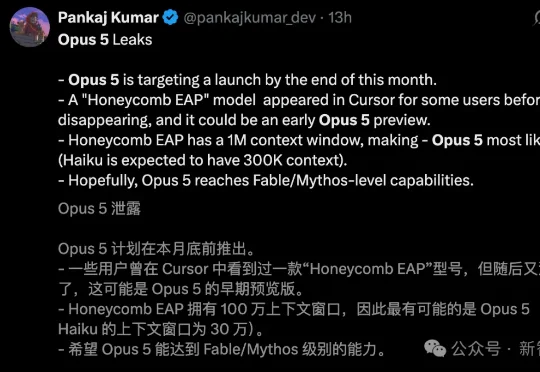
Opus 5可能要来了!有开发者意外发现,一款名为Honeycomb EAP神秘模型,1M上下文,代号「蜂巢」,在「模型列表」中短暂现身。大家一致推测,这就是Opus 5「早期预览版」,可能在月底上线。

浙江大学计算机辅助设计与图形系统全国重点实验室杜鹏团队提出了一个支持多模态输入的CAD建模智能体:CADDesigner。该智能体致力于构建一个中间层,将大模型、智能体与传统几何引擎深度融合,帮助CAD设计师提升模型设计能力和生产效率。
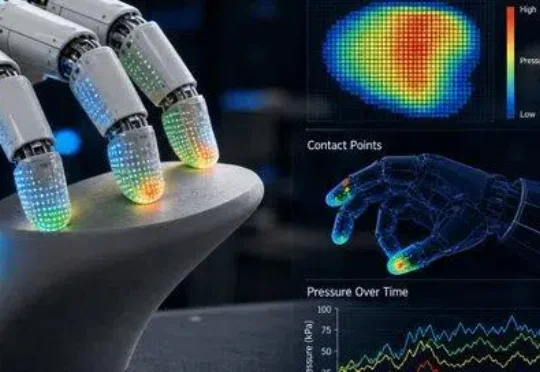
瞄准这类 “看起来做对了,物理上却没完成” 的失败。破晓智能(PHANES AI)创始人、哈工大(深圳)长聘教授杨朔及其团队发布了最新论文 TouchWorld: A Predictive and Reactive Tactile Foundation Model for Dexterous Manipulation。
WorkBuddy最近很火,实测下来的体感是,harness层似乎搭建得还不错,而且对国内模型的兼容度都做得很好,少有的国内应用厂商做出来的、基于国产模型的可用Agent产品。 这篇文章来自 Work

Databricks的联合创始人兼CEO Ali Ghodsi最近整了一个大活。公司有1.1万名员工,AI相关的开销越来越高,到底该用哪个模型搭配哪种执行框架,才能在省钱的同时保住效果?自己动手做了一次大规模测试。这次测试基于Databricks真实的业务代码,覆盖3家主流云厂商,由3000多名工程师的实际工作产出支撑,涉及多种编程语言和任务类型。

就在这届Bilibili World上,英伟达首次面向大众玩家展示了搭载RTX Spark超级芯片的笔记本电脑。这款芯片专为个人智能体打造,不仅搭载了Blackwell RTX GPU,连CPU也是出自英伟达的Grace CPU。
大模型竞技场的 AI 能力负责人 Peter Gostev,在前几天公开了 63 条几乎是故意为难模型的 3D 提示词;从大型 3D 世界,到各种可游玩的 3D 场景、名画世界,以及极端视角、自然奇观,和元素与宇宙终局场面等。