
被困在考场里的大模型
被困在考场里的大模型昨天,大名鼎鼎的 Claude 4.8 发布了。 科技圈照例是一片欢呼。 看官方放出来的一堆评测数据,依然是碾压级别的,尤其是说代码(Coding)能力有了史诗级的提升,简直像交了一份满分答卷。
来自主题: AI资讯
8837 点击 2026-05-30 10:50
 搜索
搜索
昨天,大名鼎鼎的 Claude 4.8 发布了。 科技圈照例是一片欢呼。 看官方放出来的一堆评测数据,依然是碾压级别的,尤其是说代码(Coding)能力有了史诗级的提升,简直像交了一份满分答卷。
Bloomberg 曝出重磅消息:Trump 政府正在起草一份全新 AI 安全行政令。草案中没有强制模型测试条款,也不会要求前沿 AI 模型在发布前获得政府批准,取而代之的核心方向是「自愿合作」。从 Biden 时代的强制红队测试报告机制,到如今强调企业自愿参与网络防御——美国 AI 安全监管正在经历一次路线级别的转向。
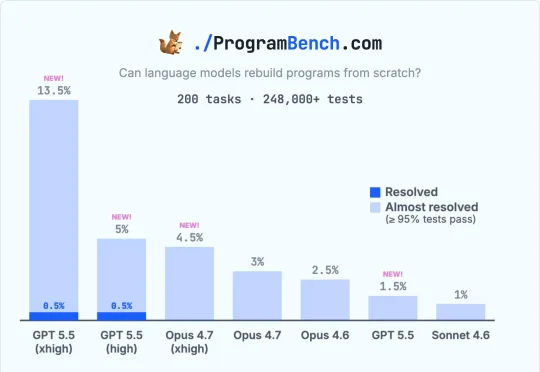
全网AI交白卷的地狱级基准,被GPT-5.5拿下一血!开局0源码盲写程序,拉满推理算力直接满血通关。传统代码测试已废,通往ASI的算力狂飙正式打响。

SWE-Bench 的创建者,刚刚又放出了一个地狱级新 benchmark。

SWE-Bench上能拿72%的模型,换张考卷直接归零!Meta联合斯坦福、哈佛放出ProgramBench,200个项目从零手写,9大顶级模型完整通过率0%。最强的Claude Opus 4.7平均通过率也才51.2%。更离谱的是一联网,就有模型在36%的任务里跑去GitHub扒源码。
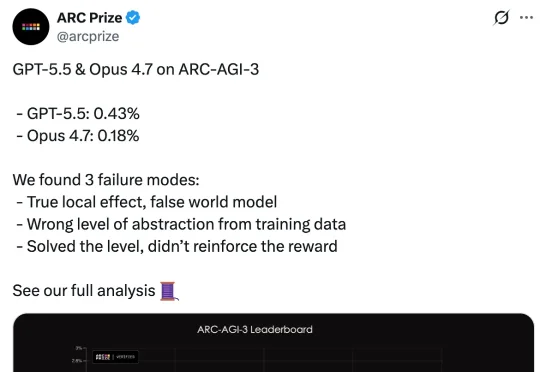
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。

当大模型训练进入深水区,竞争的关键已经不再只是「模型参数怎么调」,而逐渐转向一个更核心、也更难系统解决的问题:模型在训练过程中究竟看到了什么数据、以什么比例看到、哪些样本应该被更频繁地学习。

Midjourney 今天凌晨突然在 Alpha 平台上线 V8 模型测试版,速度暴涨5倍,支持原生2K分辨率,文本渲染大幅改进。官方推文12小时内狂揽131万浏览。但有用户花6小时测试后发现:RAW模式翻车,抽象艺术创作反而更难了。这次更新是王者归来,还是另有隐情?
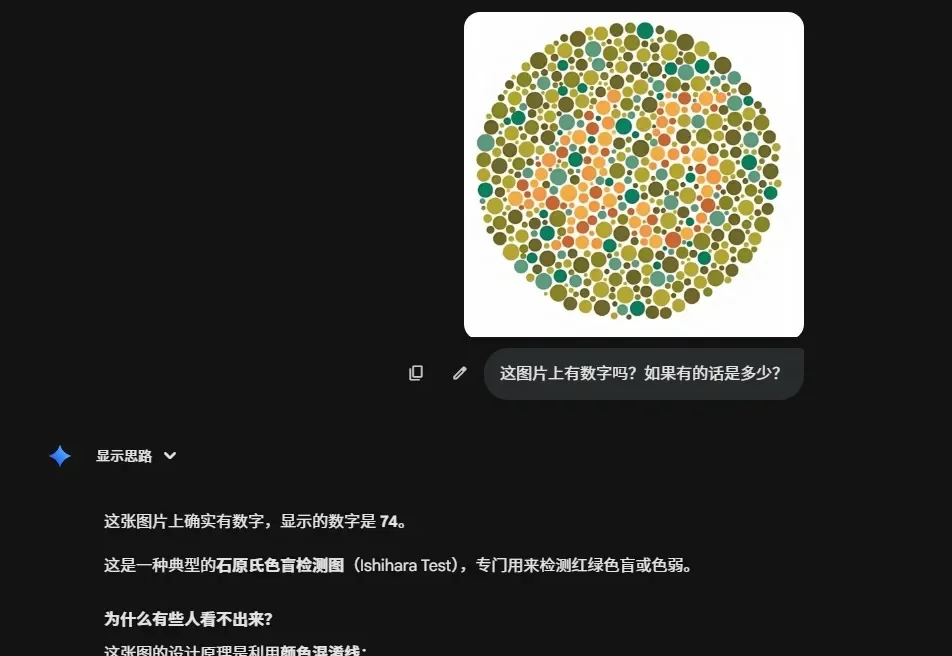
AI,是色盲吗?

AI 语音模型测试第三弹。