
AI也会「看人下菜」?Anthropic勾勒出了Claude的价值观画像
AI也会「看人下菜」?Anthropic勾勒出了Claude的价值观画像同一个问题,换一种语言问 Claude,得到的可能不只是措辞不同的答案。
来自主题: AI资讯
7367 点击 2026-07-14 15:52
 搜索
搜索
同一个问题,换一种语言问 Claude,得到的可能不只是措辞不同的答案。

曾经我们对 AI 的期待还比较朴素,写邮件、翻译论文、聊天搭子……那时候,AI 像一个初出茅庐的实习生,你指哪它打哪,但也经常一本正经地胡说八道。
近日,自监督学习新工作 VISReg(Variance-Invariance-Sketching Regularization)获图灵奖得主 Yann LeCun 连续转发并给予高度认可 —— 他在转发时评价道「VICReg begat SIGReg which begat VISReg」(VICReg 孕育了 SIGReg,SIGReg 又孕育了 VISReg),

7月6日,腾讯混元Hy3正式版发布。
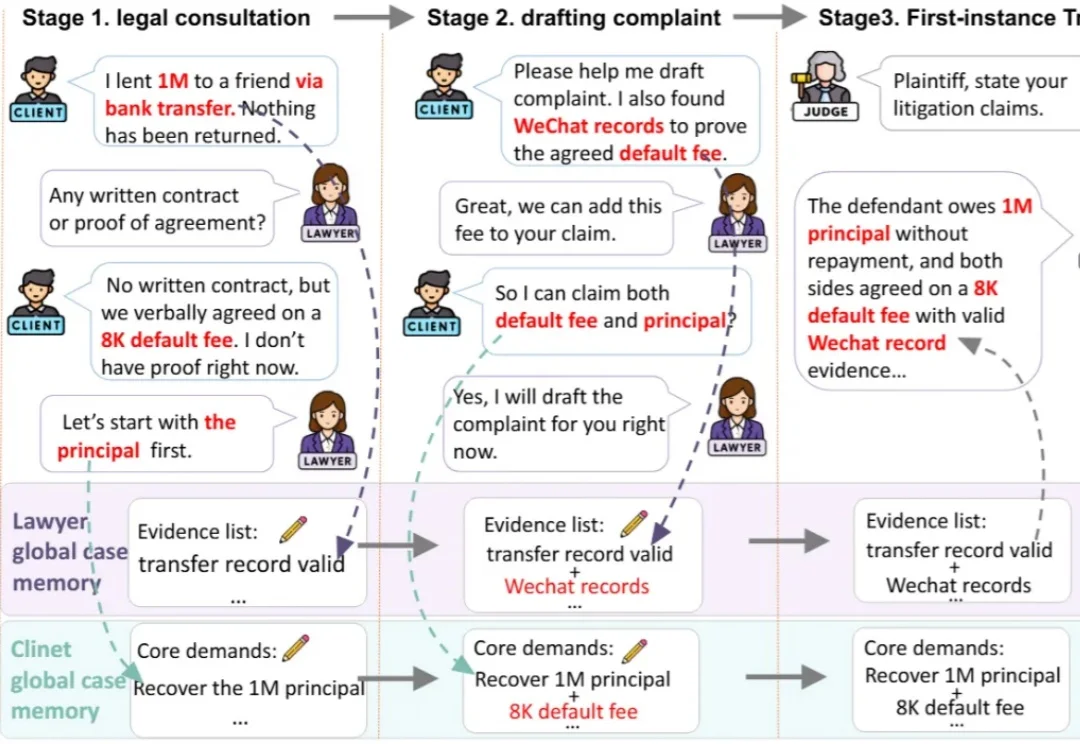
打官司,从来不是一问一答就能结束的事。
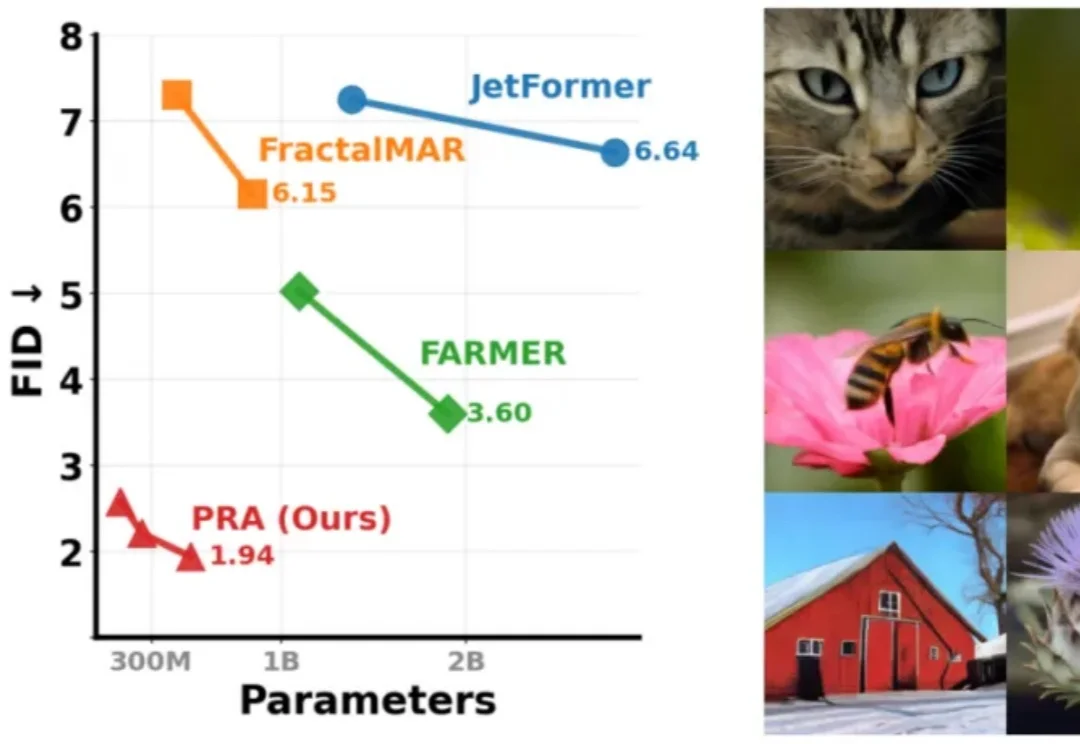
过去几年,扩散模型几乎定义了高质量图像生成:从随机噪声出发,经过多轮迭代,逐步 “雕刻” 出一张图像。但随着大语言模型席卷人工智能领域,另一条路线正迅速走到舞台中央 —— 图像,能否也像语言一样,通过自回归方式逐步生成?

不教AI认手,而是从视频世界模型里直接「读」出双手:三大基准SOTA,让百万小时野生视频第一次能变成机器人的操作教材。
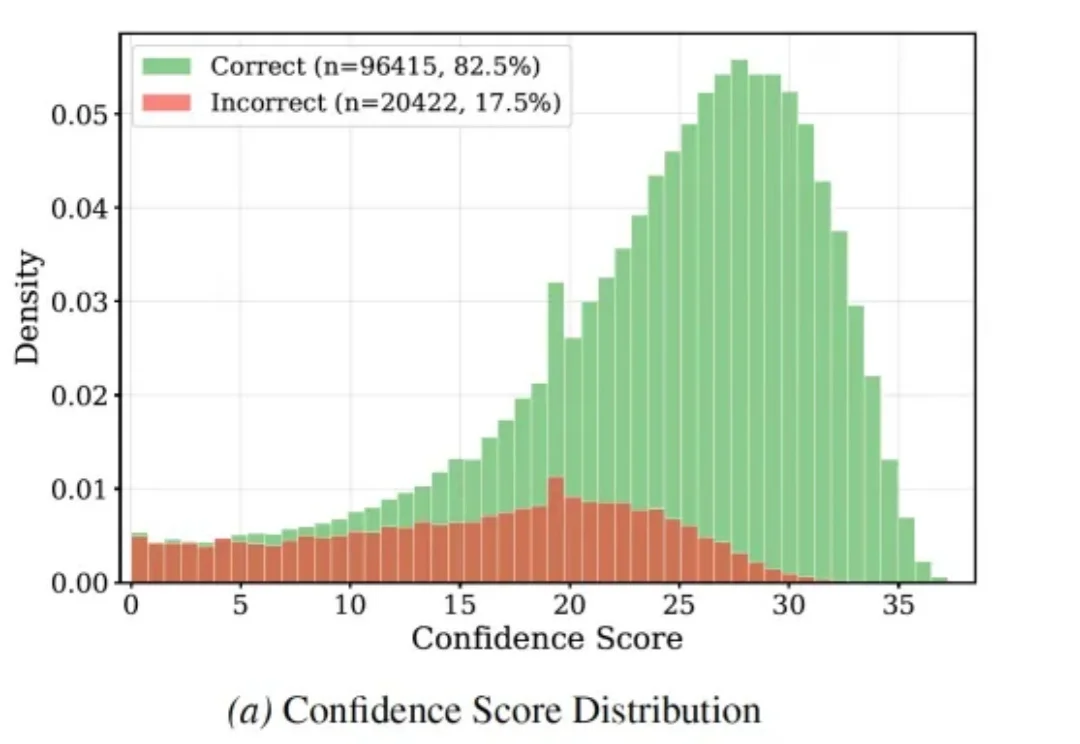
奖励模型(Reward Model, RM)是大语言模型对齐的核心组件,负责为模型输出提供符合人类偏好的评价信号。现有方法各有短板:标量判别式 RM 高效稳定但可解释性有限;生成式 judge 能给出判断理由,却需为每个样本生成长 reasoning,token 与延迟开销显著。

近期,围绕「世界模型」的讨论持续升温。机器人、自动驾驶、视频生成、具身智能等多个方向都在频繁使用这一概念,相关系统不断出现,演示形式日益丰富,评价指标也越来越多。伴随这一趋势,一个基础问题变得格外重要:当一个模型被称为「世界模型」时,人们究竟在评价什么?
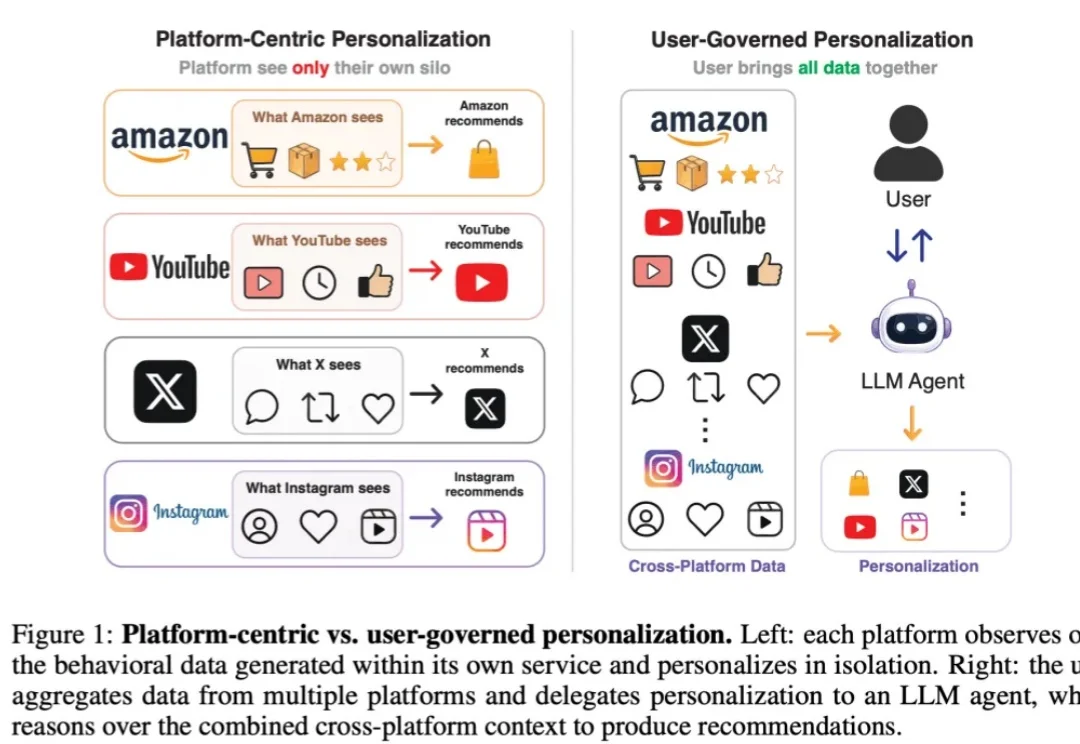
在过去二三十年的互联网发展中,个性化推荐几乎一直是平台的核心能力之一。打开视频 app,平台决定你接下来会刷到什么视频;打开购物软件,平台预测你可能会购买什么商品;打开短视频 app,平台根据你的浏览、点赞、停留和互动,不断优化信息流。某种意义上,现代互联网的用户体验本身就是由推荐系统塑造的。