
独家|清华系初创完成数亿元种子轮融资:我们不想被贴上「世界模型」的标签
独家|清华系初创完成数亿元种子轮融资:我们不想被贴上「世界模型」的标签新时代的 Physical AI 公司,不是本体公司,也不是模型公司。
来自主题: AI资讯
10529 点击 2026-06-30 15:41
 搜索
搜索
新时代的 Physical AI 公司,不是本体公司,也不是模型公司。

独家获悉,清华系初创公司「厘清智能」宣布完成数亿元种子轮融资,投资方阵容堪称豪华:由顺为资本、红杉中国、高瓴创投、峰瑞资本、星连资本、水木清华校友种子基金、SEE FUND等一线基金,与智元机器人、灵心巧手、世纪金源等产业资本共同投资。其中,顺为资本与红杉中国更是连续多轮追加投资。

如今,大模型越来越擅长回答问题了,但当 AI 不再只停留在聊天窗口,而是走向智能眼镜、可穿戴设备乃至家庭机器人时,问题会随之改变。用户未必有时间把需求完整说出来,也未必希望助手随时插话。更理想的助手,应该能在现场真正理解人,在用户需要的时候出现,在不合适的时候保持安静。
清华系物理AI企业「清研精准」已于近日完成数亿元B3轮融资,本轮融资由北京市绿色能源基金、北汽产投领投,裕隆集团跟投。据悉,该轮资金将会用于核心人才招募、多模态数采设备的研发与规模化部署,以及算力采购与模型训练基础设施建设等方向。

来自 Sharpa、清华大学、UC Berkeley、上海交通大学、ETH Zurich 等机构的研究者提出了首个通用触觉基础策略 FTP-1。它基于约 3,000 小时、来自 26 个数据来源和 21 种触觉传感器的数据进行预训练

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?

公司由姚颂联合正大集团、清华青年学者于超共同发起,定位为物理智能系统公司,通过世界动作模型(WAM)与强化学习技术,推动机器人在真实商业与工业场景中落地,最终成为一个可信赖的机器人服务提供商。目前已完成近亿美元天使轮系列融资,投资方包括正大集团、华勤技术、九安医疗等多家上市企业,多位国内与国际知名企业家,以及多家一线投资机构。
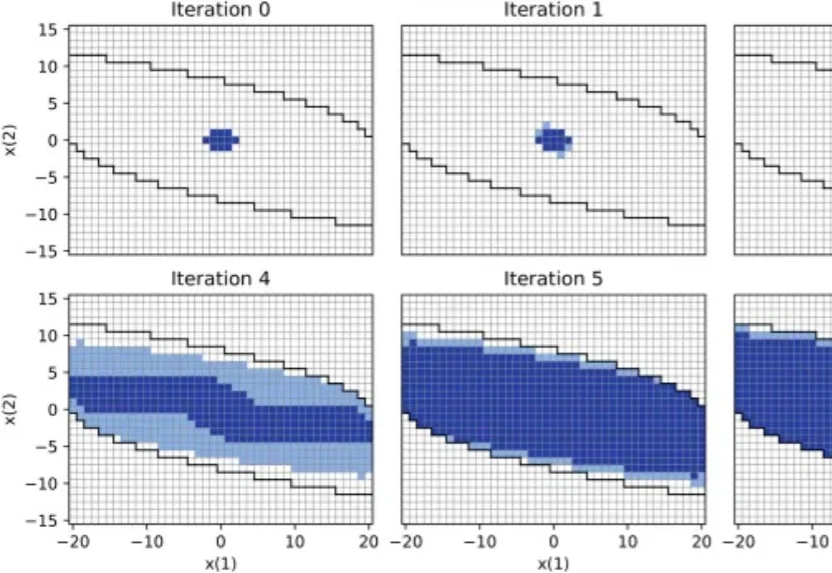
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。

当 AI 智能体真正开始干活,它的每一次请求,都要经过一个你看不见的「中间人」。

机器狗去买咖啡,轮椅跟人抬杠:清华现场0遥操、全靠现挂。完全没有剧本,在清华现场,这群机器人直接把物理AGI第一幕演活了!