
Google「白送」开发者每分钟 100 万 tokens?12 万人围观后,真相让人五味杂陈
Google「白送」开发者每分钟 100 万 tokens?12 万人围观后,真相让人五味杂陈0 美元你能得到什么——Gemini 2.5 Flash 和 Pro 均可用,每分钟 1M tokens,原生支持文本、图像、音频、视频多模态输入 ,几秒钟生成 API Key,即开即用
来自主题: AI资讯
11002 点击 2026-06-30 13:56
 搜索
搜索
0 美元你能得到什么——Gemini 2.5 Flash 和 Pro 均可用,每分钟 1M tokens,原生支持文本、图像、音频、视频多模态输入 ,几秒钟生成 API Key,即开即用
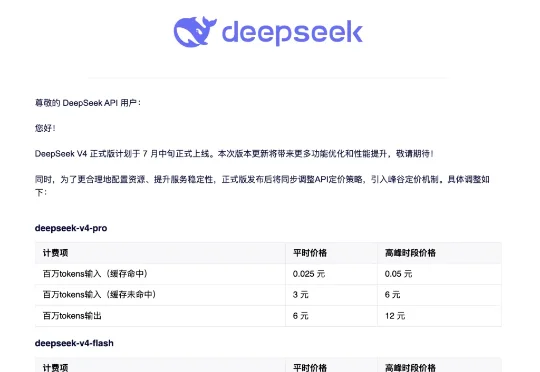
记者获悉,DeepSeek宣布价格调整,引入峰谷计费机制:以DeepSeek-v4-pro为例,其输入价格(缓存命中)平时为0.025元/百万tokens,高峰时期为0.05元/百万tokens;输入价格(缓存未命中)平时为3元/百万tokens,高峰时期为6元/百万tokens;输出价格平时为6元/百万tokens,高峰时期为12元/百万tokens。

全球大模型的军备竞赛,正在“智商”之外开辟新的战场—— 推理速度。
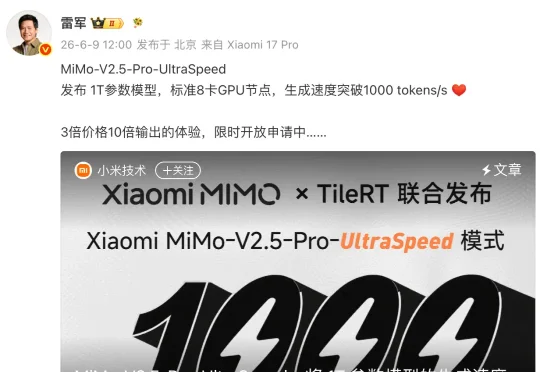
今日,小米MiMo团队与推理系统团队TileRT联合宣布,Xiaomi MiMo-V2.5-Pro的UltraSpeed模式已实现万亿参数(1T)旗舰模型输出速度首次突破1000 tokens/s。
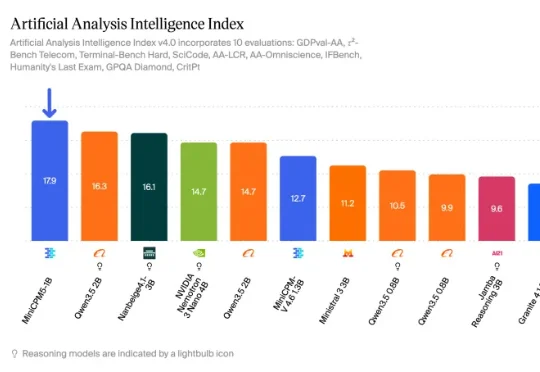
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。一共是两份 L3 级数据集:Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。

每周25万亿tokens的真实流量、估值一年翻倍——OpenRouter拿下1.13亿美元B轮融资。

近年来,Chain-of-Thought(CoT)推理已经成为提升大语言模型和多模态大语言模型复杂问题求解能力的重要技术路径。

智能体时代的核心是算力。
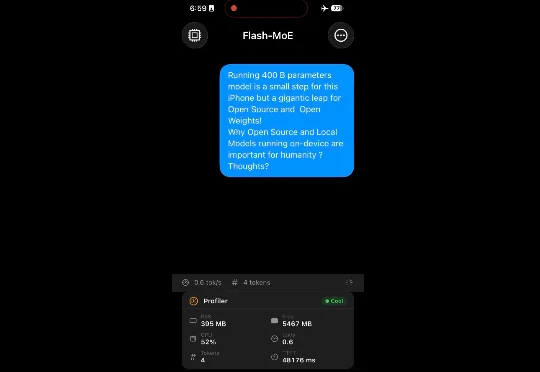
刚看到这个 Demo 的时候着实有些想笑,很久没有见过吐词如此之慢的大模型了。观感上就像「闪电」老师。尽管只有每秒 0.6 个 tokens 的输出速率,这依旧是一个令人不可思议的工作。因为这是一个跑在 iPhone 17 Pro 上的 400B 大模型!

昨晚,DeepSeek-V4又降价了,全系两款模型输入缓存命中的价格直接降至首发价格1/10。最新调价后,DeepSeek-V4-Flash每百万tokens输入(缓存命中)价格为0.02元,DeepSeek-V4-Pro为0.025元。